










With the rise of digital-first experiences, companies are grappling with more data than ever before. Gartner notes that 70% of organizations using cloud services today plan to increase their cloud spending to support digital experiences. They elaborate by stating “Cloud adoption therefore becomes a significant means to stay ahead in a post-COVID-19 world focused on agility and digital touch points.”
Given the rapid adoption of cloud technologies, integration with core private cloud and on-premise operations is a critical requirement. This is where modern database replication platforms will play a significant role to enable this strategy.
What is Data Replication?
Data replication is the process of copying data at different physical and virtual location in a manner where each instance of the data is consistent – increasing availability and accessibility across networks. There are several technical implications and caveats of data replication including consistency tradeoffs between eventual consistency versus and strong consistency in the context of a single distributed system.
What is Database Replication?
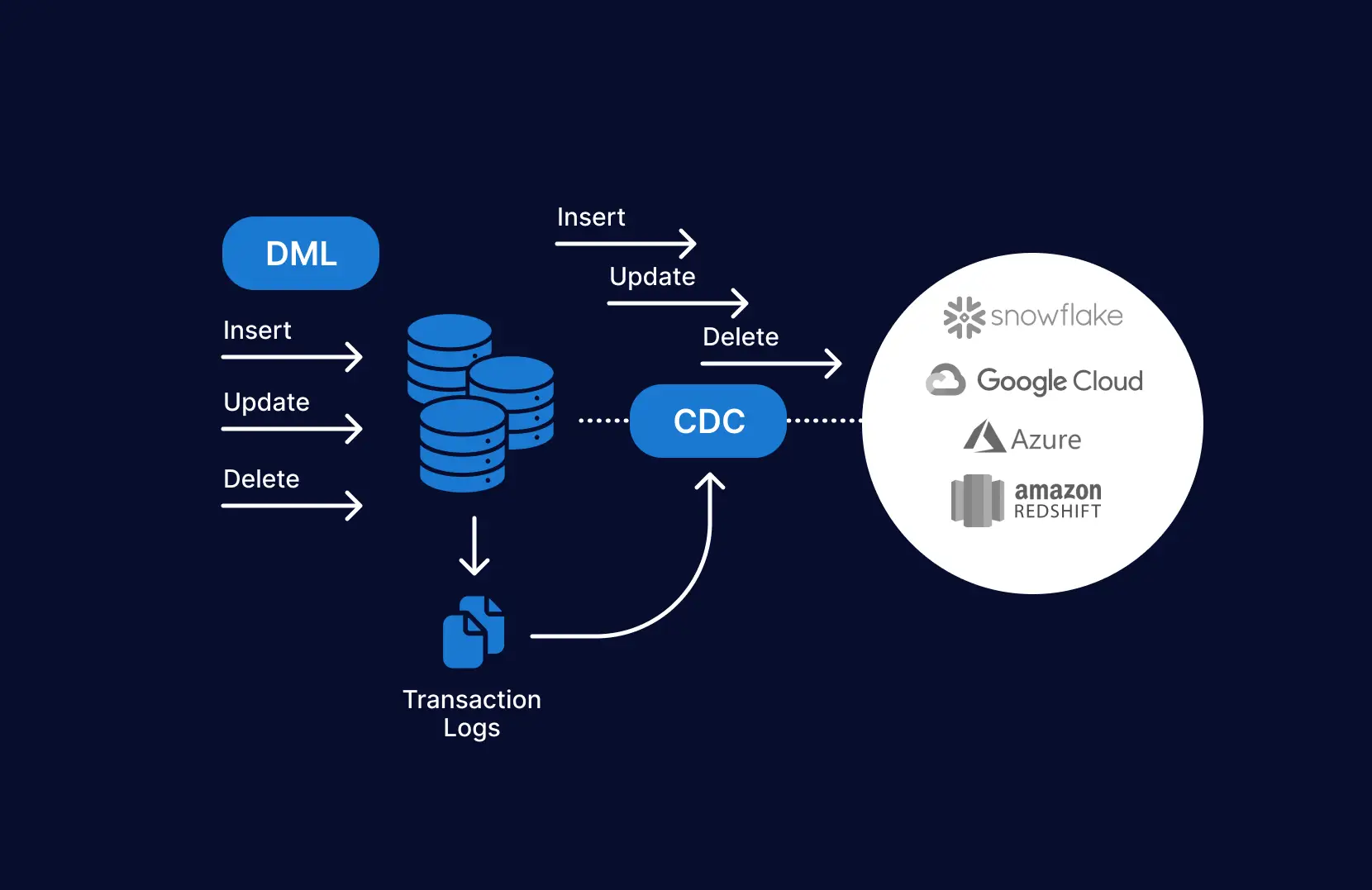
Database replication is the process of copying data from a source database to one or more target databases. A widely-used approach for database replication is replaying the data manipulation language (or DML) statements from the source database to the relevant targets with minimal latency to ensure data is consistent across each instance.
Database Replication in a Distributed World
In a multi-instance cloud environment with endless distributed applications, file systems, storage systems, databases, and data warehouses, every enterprise is striving to implement a single source of truth to drive their analytics and operations.
Yet as industry thought leader and lauded database researcher Dr. Michael Stonebraker notes, “One size does not fit all.” . The key to supporting diverse data management operations and analytics at scale is a modern data replication strategy.
However, as Striim Co-Founder and EVP of Product Alok Pareek notes in his lecture at Boston University’s Department of Computer Science , there is significant complexity in handling change streams to reliably deliver database replication for real-world use cases.
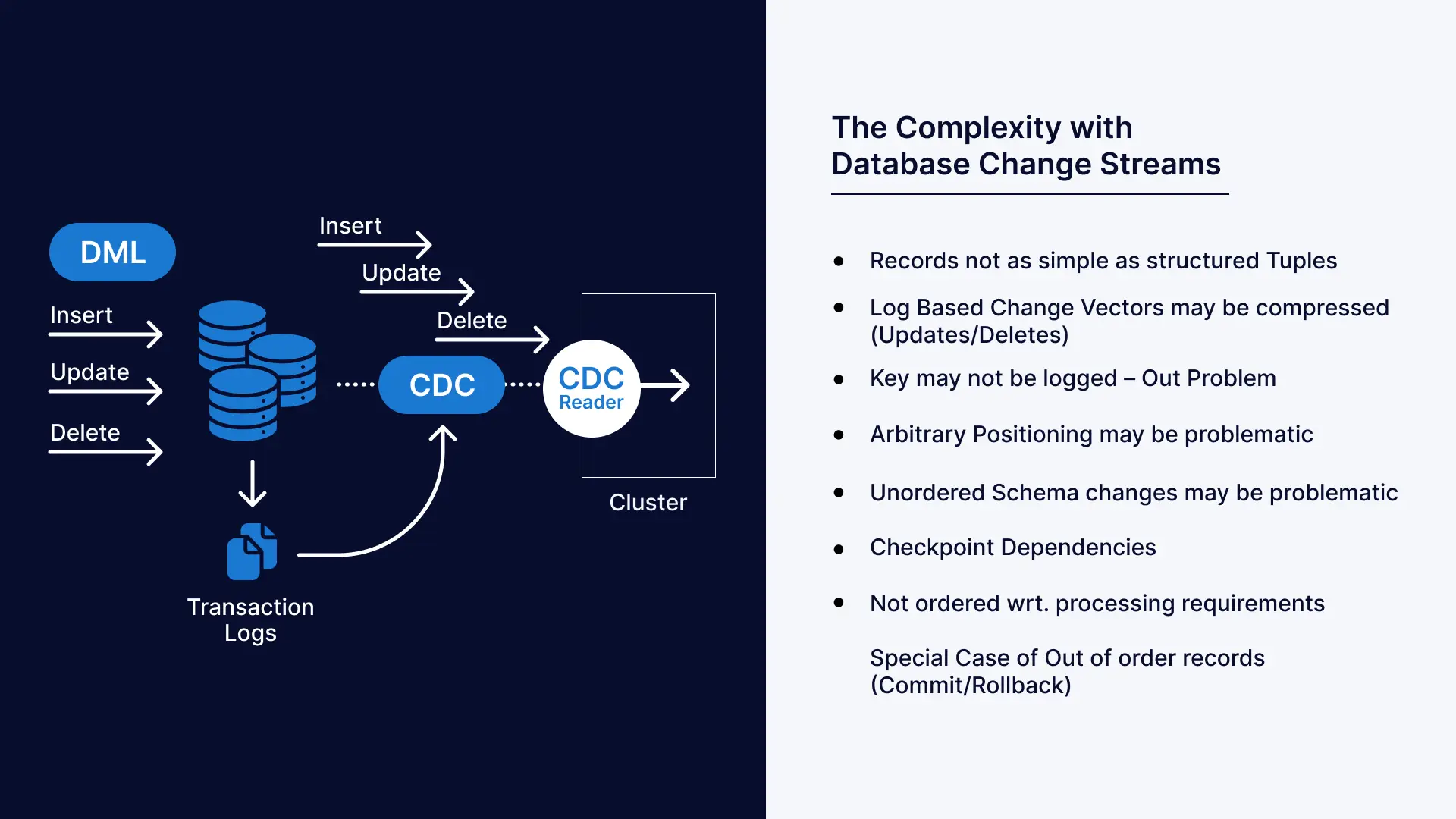
We will elaborate on how those challenges are addressed in the section below, but first we will provide some context on the problem.
Why Data Replication?
Reliable data replication in a digital-first world is critical to every business. In retail, it can be the difference between a sale and an abandoned cart, a blocked suspicious transaction versus thousands of dollars lost in fraud, and an on-time delivery versus a lost package.
8 Key Categories to Evaluate Modern Database Replication Platforms
There are 8 key feature categories to consider when looking at modern data replication platforms to support digital-first experiences and cloud adoption. The high level goals of these features should deliver the following
- Low latency replication
- Distributed architecture
- Support Replication across private and public clouds
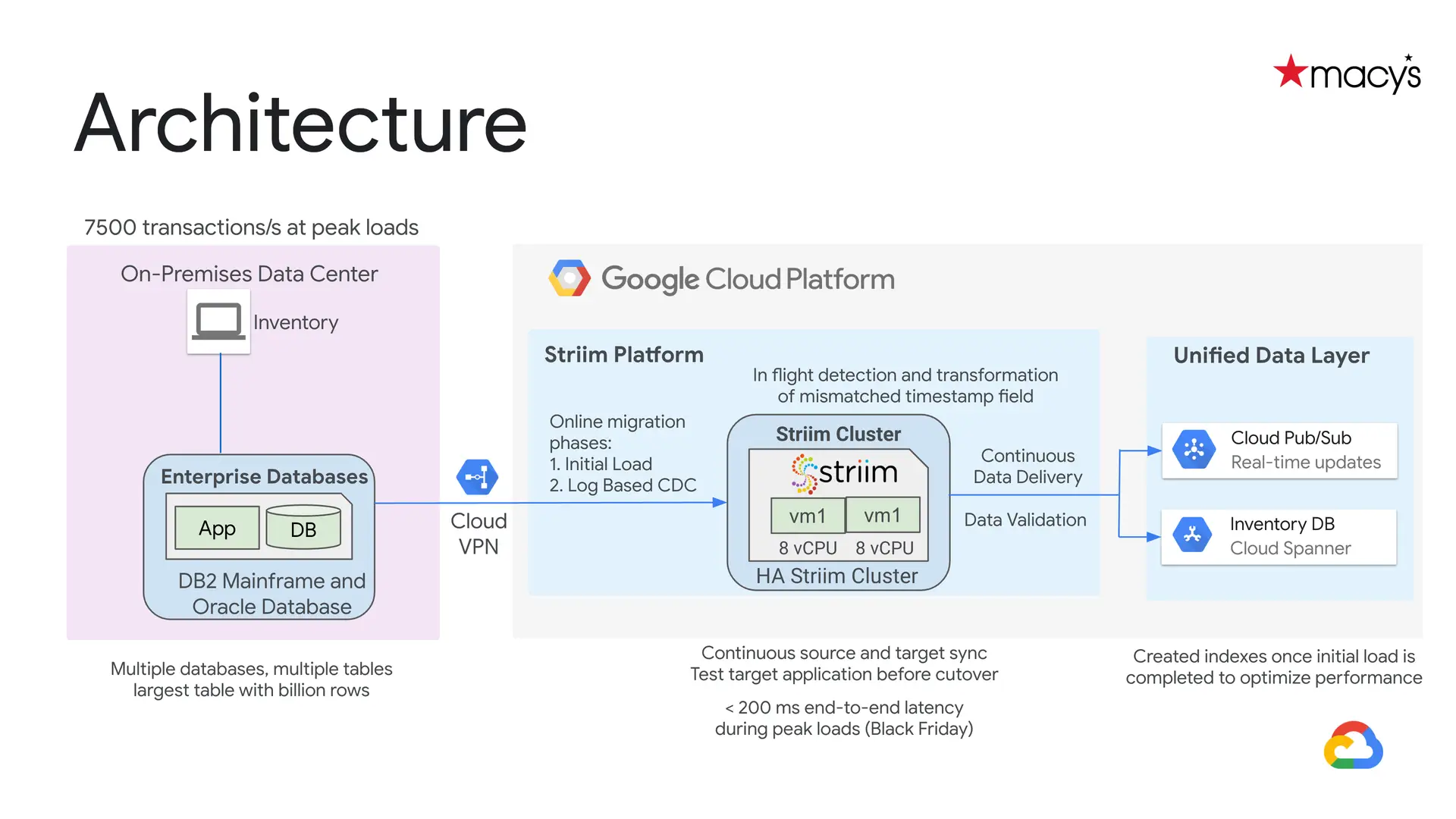
One real world example of a modern database replication architecture is Macy’s implementation that uses Striim for replication to Google Cloud. Macy’s approach can handle peak, holiday transaction workloads:
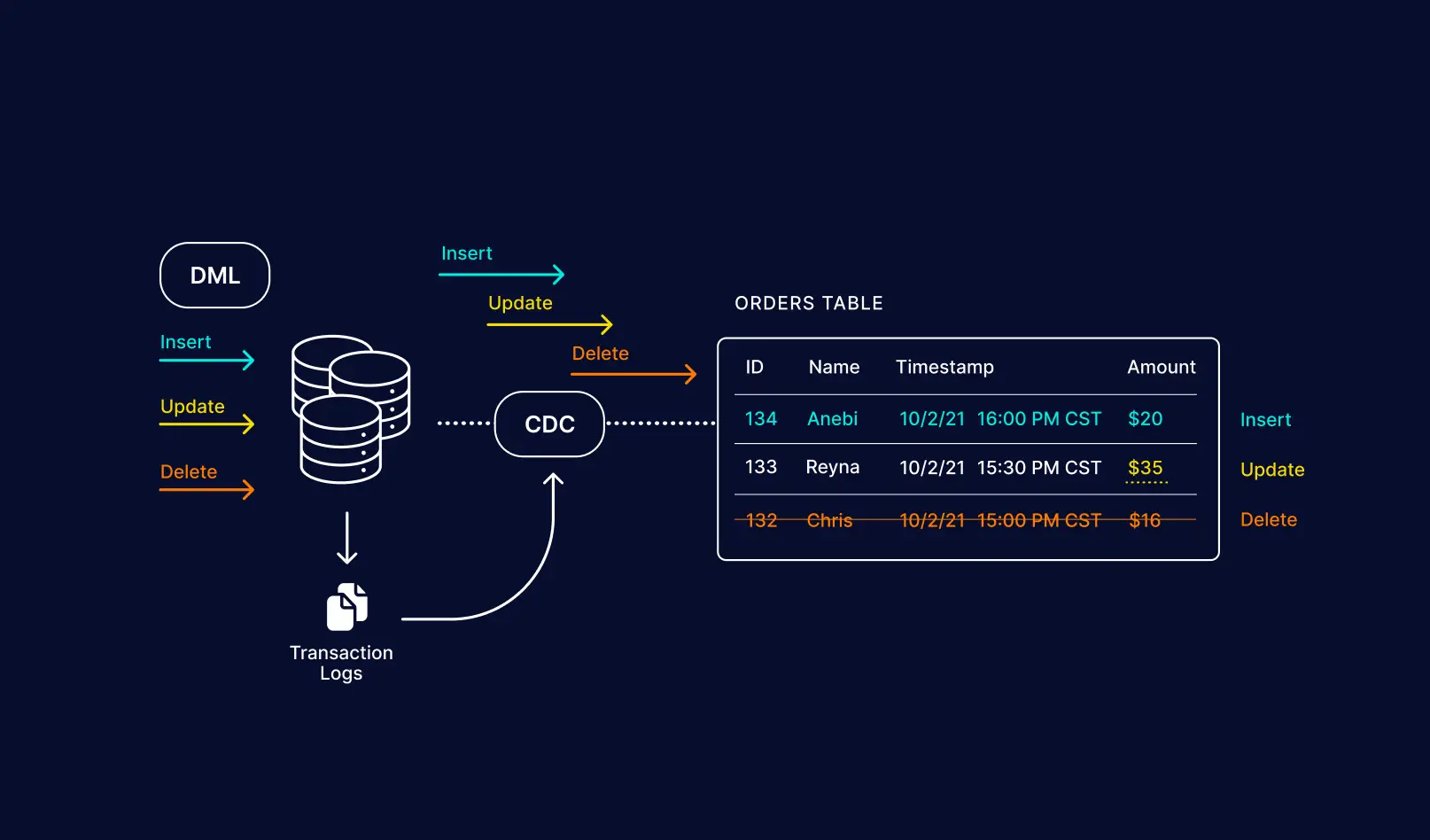
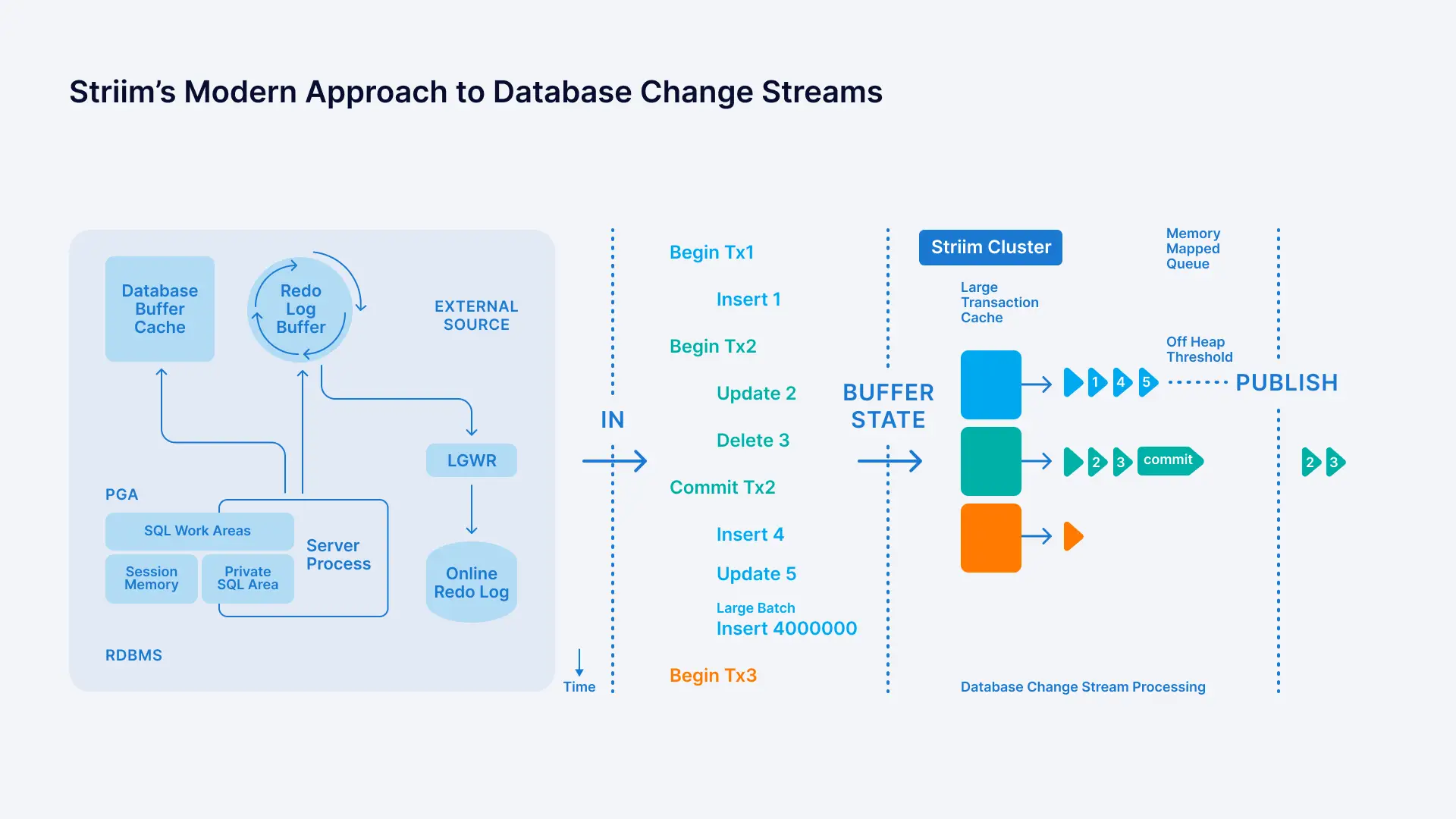
1. Change data capture
The ability to mine transaction logs and change-data from applications in real-time is the core requirement of data replication platforms. While change data capture (or CDC) has been around for decades, modern implementations take into account new interfaces to change streams.
This allows companies to build change data capture topologies that meet the scale of distributed cloud platforms. Striim’s ground-up, distributed architecture widely separates itself from legacy CDC tools that rely fully on brittle, file-based buffering.
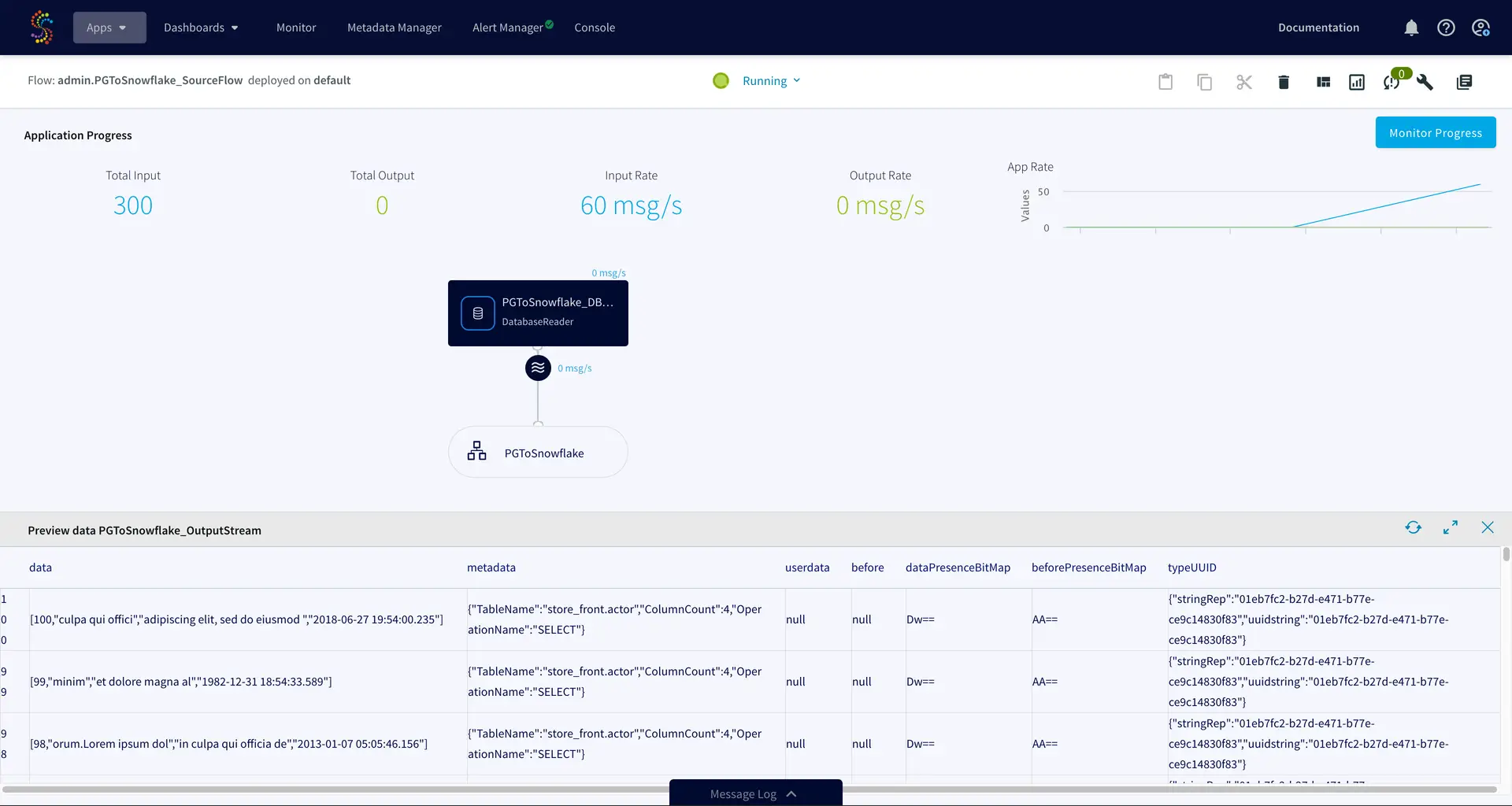
2. Observable data at every step
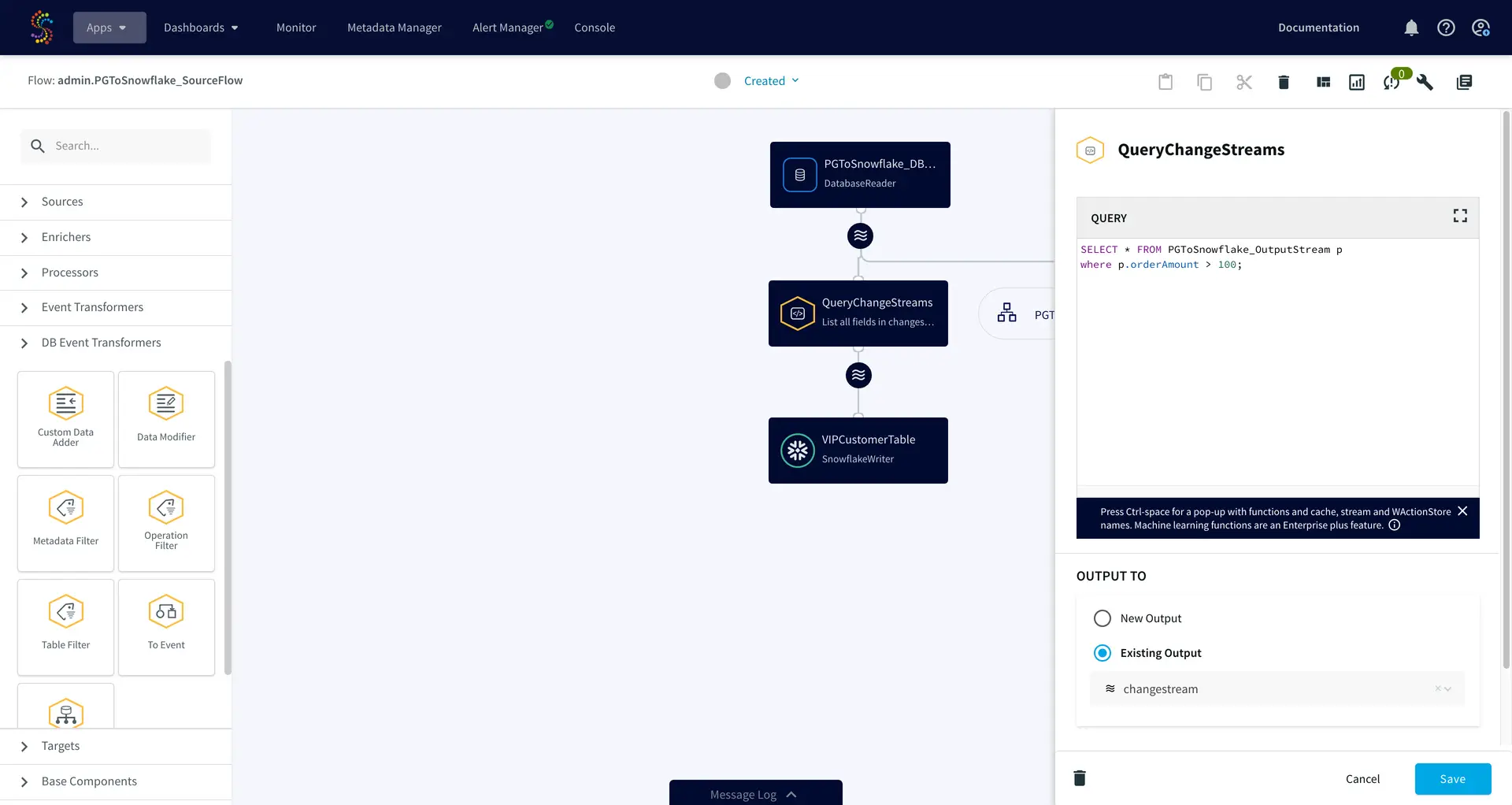
3. SQL-based access and transformation of real-time data
When combining data across multiple sources into a single ‘source-of-truth’, modern data replication solutions be able to transform data with SQL-constructs that data managers are already proficient with.
4. Horizontally scalable
Here is just a short list of tools in a modern data stack are built to scale horizontally on commodity hardware
- Azure PostgreSQL Hyperscale
- BigQuery (fully managed)
- Databricks
- Apache Kafka
- Apache Spark
- MongoDB
- MariaDB
- Snowflake (fully managed)
- And the list goes on…
See a trend here?
Yet legacy database replication tools are built to scale vertically on a single machine. This was suitable for the era of scaling cores vertically on proprietary machines running on-premise, but does not meet the needs of modern data management.
A modern database replication solution should support multi-node deployments across clouds to help unify your data at scale with maximum reliability.
5. A single view of metadata across nodes
Building on to the last point – a horizontally distributed replication platform would be impossible to manage without a single, queryable view into your objects.

6. Data delivery SLAs for minimum latency
In the example noted above, Macy’s modern replication stack was built to deliver end-to-end latencies under 200 milliseconds – even with Black Friday loads of 7500+ transactions per second (or 19 billion transactions a month). Choosing a data replication platform that can handle peak loads and monitor latency is critical to operate at scale.
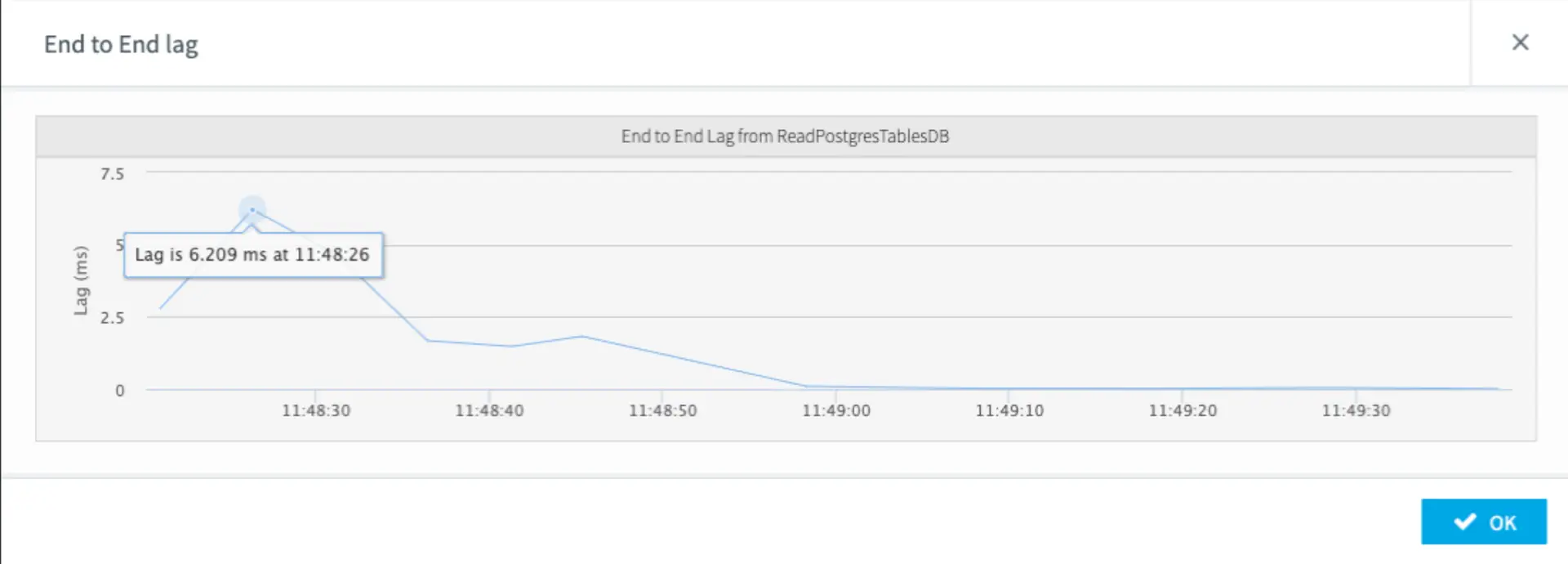
7. Flexibility between ETL and ELT
A modern data replication tool should give users the choice to rely on external transformation tools like DBT when applicable. However, in the case of low-latency transformation requirements and custom EtLT, modern database replication should support streaming transformations. In some cases data needs to be formatted and transformed just to adhere to the format of the target data warehouse. In those cases ELT is not a suitable solution.
8. Data validation at scale
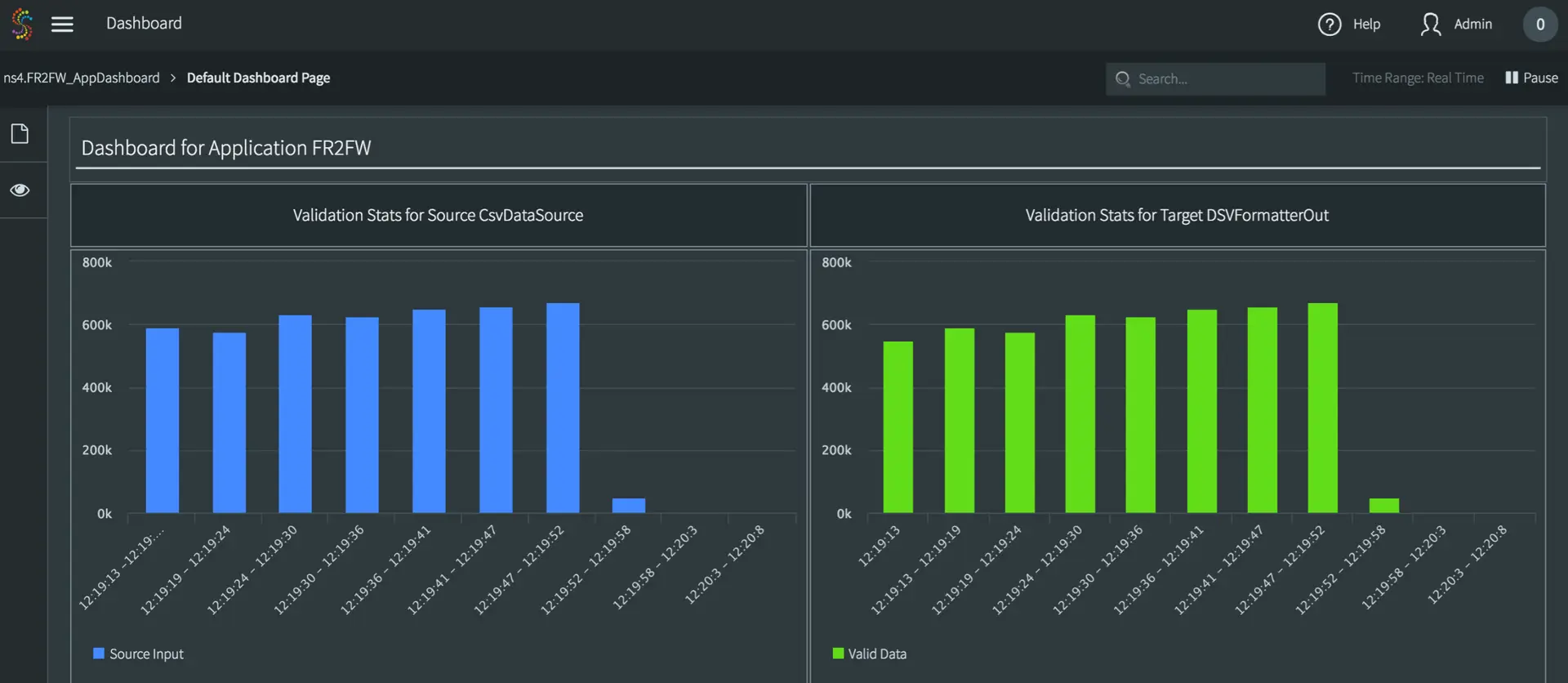
Modern data replication platforms should give users the ability to query data validation statistics to ensure all data read from a source application are successfully written to their target platform. A practical use case would be reporting organization-wide data reliability. If your data validation dashboard shows that your source database is hours behind your target data warehouse, you can immediately notify other orgs that data may be stale while you triage the issue with root causes ranging from a server outage or bottlenecked resources in the data warehouse.




