










Both data warehouses and data lakes have been serving companies well for a long time. Despite their pros, each also has its limitations. That’s why data architects envision a single system to store and use data for varying workloads. This is where a data lakehouse has emerged as a major problem-solver in the last few years.
A data lakehouse can help organizations move past the limitations of data warehouses and data lakes. It lets them reach a middle ground where they can get the best of both worlds in terms of data storage and data management.
What is a data lakehouse?
A data lakehouse shores up the gaps left by data warehouses and data lakes — two commonly used data architectures. To understand how a data lakehouse works, let’s first take a brief look at data warehouses and data lakes.
Defining data warehouses
A data warehouse collects data from various data sources within an organization to extract information for analysis and reporting. Usually, data warehouses pull data from databases, which have a specific structure known as schema. This data gets processed into a different database format that’s optimized for BI (business intelligence) use cases, where it’s more effective for complex queries.
This data warehouse process has its advantages. It prioritizes certain factors, such as the integrity of the provided data. However, this approach comes with several drawbacks, including the higher costs due to maintenance and vendor lock-in, necessitating the need for more cost-effective data management approaches.
Defining data lakes
The data lake was invented in 2010 and rapidly gained mainstream adoption throughout the 2010s. Unlike a data warehouse, a data lake is more adept at processing unstructured data, so it can be used for data analytics. This is the data companies can gather from web scraping, web APIs, or files that don’t follow the structure of a relational database.
In addition, data lakes store data at a more affordable rate. That’s because data lake is installed on low-cost hardware and uses open-source software. But data lakes don’t offer all the features offered by a data warehouse. Consequently, contrary to a data warehouse, the data might be lacking in terms of integrity, quality, and consistency.
Combining the advantages of both into a data lakehouse
A data lakehouse offers the best of both worlds by combining the best aspects of data warehouses and data lakes. Similar to a data warehouse, it offers schema support for structured data and keeps data consistent by supporting ACID transactions.
And like data lakes, a data lakehouse can handle unstructured, semi-structured, and structured data. This data can be stored, transformed, and analyzed for text, audio, video, and images. Finally, data lakehouses offer a more affordable method of storing large volumes of data because they utilize the low-cost object storage options of data lakes to cut costs.
What problems can a data lakehouse solve?
Many organizations use data warehouses and data lakes with plenty of success. However, certain problems show up in certain cases.
- Data duplication: If a company uses many data warehouses and a data lake, then it’s bound to create data redundancy — when the same piece of data is stored in two or more separate places. Not only is it inefficient, but it may also cause data inconsistency (when the same data is stored in different versions in more than one table). A data lakehouse can help consolidate everything, remove additional copies of data, and create a single version of truth for the company.
- Siloes between analytics and BI: Data scientists use analytics techniques on data lakes to go through unsorted data, while BI analysts use a data warehouse. A data lakehouse helps both teams to work within a single and shared repository. This aids in reducing data silos.
- Data staleness: According to a survey by Exasol, 58% of companies make decisions based on outdated data. Data warehouses are part of the problem because it is generally expensive to constantly process and refresh real-time data. A data lakehouse supports reliable and convenient integration of real-time streaming along with micro-batches. This makes sure that analysts can always use the latest data.
The common features of a data lakehouse
A data lakehouse aims to improve efficiency by building a data warehouse on data lake technology. According to a paper from Databricks, a data lakehouse does this by providing the following features:
- Extended data types: Data lakehouses have access to a broader range of data than data warehouses, allowing them to access system logs, audio, video, and files.
- Data streaming: Data lakehouses allow enterprises to perform real-time reporting by supporting streaming analytics. Especially when used with streaming data integration products like Striim in concert.
- Schemas: Unlike data lakes, data lakehouses apply schemas to data, which helps in the standardization of high volumes of data.
- BI and analytics support: BI and analytics professionals can share the same data repository. Since a data lakehouse’s data goes through cleaning and integration, it’s useful for analytics. Also, it can store more updated data than a data warehouse. This enhances BI quality.
- Transaction support: Data lakehouses can handle concurrent write and read transactions and thus can work with several data pipelines.
- Openness: Data lakehouses support open storage formats (e.g., Parquet). This way, data professionals can use R and Python to access it easily.
- Processing/storage decoupling: Data lakehouses reduce storage costs by using clusters that run on cheap hardware. A lakehouse can offer data storage in one cluster and query execution on a separate cluster. This decoupling of processing and storage can help to make the most of resources.
Layers in a data lakehouse
Based on Amazon and Databricks data lakehouse architectures, a data lakehouse can have five layers, as shown below:
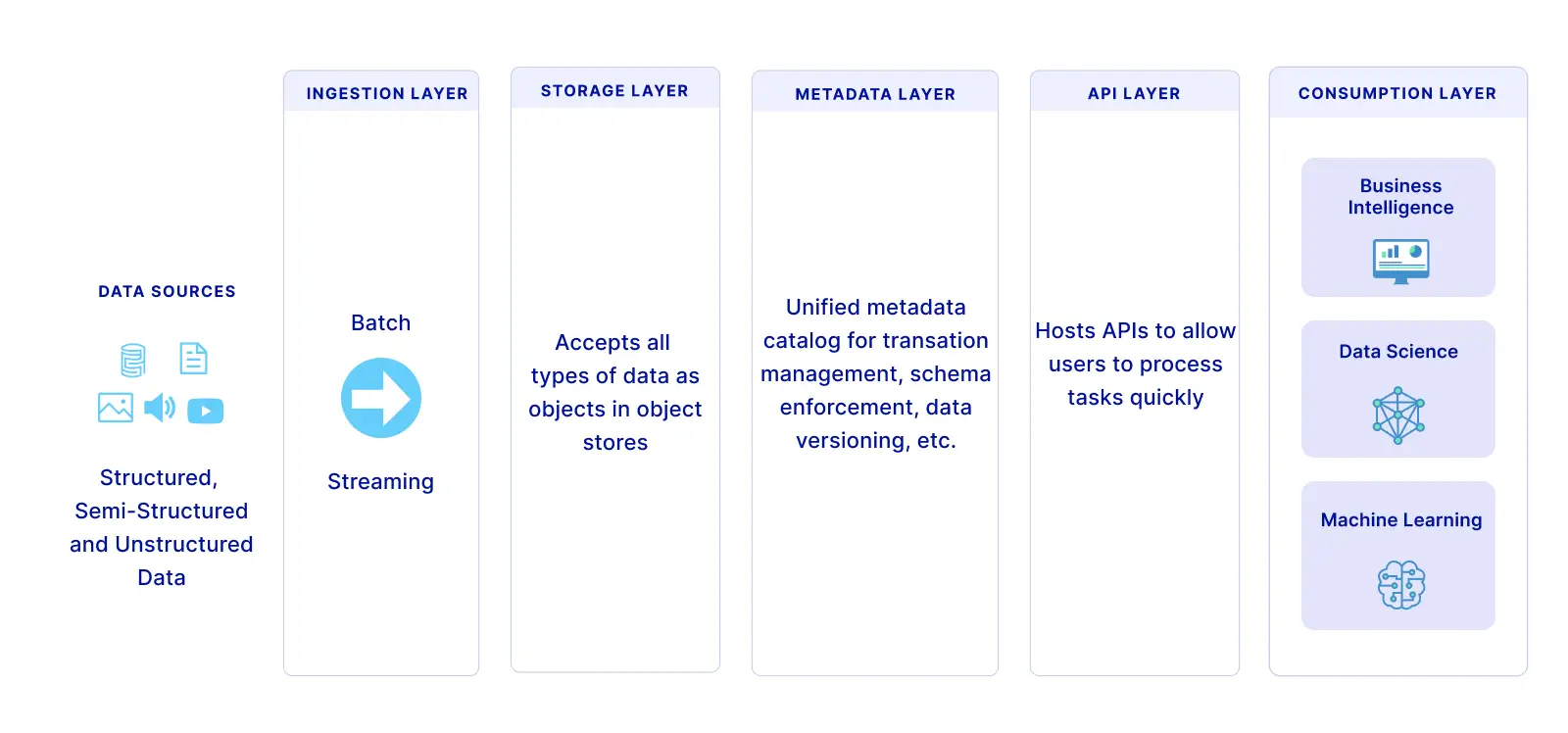
1- Ingestion layer
The first layer pulls data from multiple data sources and delivers it to the storage layer. The layer uses different protocols to link to a variety of external and internal sources, such as CRM applications, relational databases, and NoSQL databases.
2- Storage layer
The storage layer stores open-source file formats to store unstructured, semi-structured, and structured data. A lakehouse is designed to accept all types of data as objects in affordable object stores (e.g., AWS S3).
You can use open file formats to read these objects via the client tools. As a result, consumption layer components and different APIs can access and work with the same data.
3- Metadata layer
The metadata layer is a unified catalog that encompasses metadata for data lake objects. This layer provides the data warehouse features that are accessible in relational database management systems (RDBMS). For instance, you can create tables, implement upserts, and define features that enhance RDBMS performance.
4- API Layer
This layer is used to host different APIs to allow end-users to process tasks quickly and take advantage of advanced analytics. This layer produces a level of abstraction that enables consumers and developers to get the benefit from using a plethora of languages and libraries. These APIs and libraries are optimized to consume your data assets in your data lake layer (e.g., DataFrames APIs in Apache Spark).
5- Data consumption layer
This layer is used to host different tools and applications, such as Tableau. Client applications can use the data lakehouse architecture to access data stores in the data lake. Employees within a company can use the data lakehouse to perform different analytics activities, such as SQL queries, BI dashboards, and data visualization.
Leverage a data lakehouse for the right use cases
A data lakehouse isn’t a silver bullet that’ll address all your data-related challenges. It can be tricky to build and maintain a data lakehouse due to its monolithic architecture. In addition, its one-size-fits-all design might not always provide the same quality that you can get with other approaches that are designed to tackle more specific use cases.
On the other hand, there are many scenarios where a data lakehouse can add value to your organization. Data lakehouses can help you to stage all your data in a single tier. You can then optimize this data for various types of queries on unstructured and structured data. For example, if you’re looking to use both AI and BI, then the versatility of a data lakehouse can be useful. You can also use a data lakehouse to address the data inconsistency and redundancy caused by multiple systems. For more details, go through this comparison and decide which data management solution is best for you.




