










This integration post is the final blog in a six-part series on making In-Memory Computing Enterprise Grade. Read the entire series:
- Part 1: overview
- Part 2: data architecture
- Part 3: scalability
- Part 4: reliability
- Part 5: security
- Part 6: integration
The final Enterprise Grade requirement is Integration. You can have the most amazing in-memory computing platform, but if it does not integrate with your existing IT infrastructure, and provide access to existing data sources and stores, it will be useless.

There are a number of different things to consider from an integration perspective. Most importantly, you need to get data in and out. You need to be able to harness existing sources, such as databases, log files, messaging systems and devices, in the form of streaming data, and write the results of processing to existing stores such as a data warehouse, data lake, cloud storage or messaging systems. You also need to consider any data you may need to load into memory from external systems for context or enrichment purposes, and existing code or algorithms you may have that may serve as a component of your in-memory processing.
For us, integration was essential because Striim is an in-memory analytics platform, and for many of our customers, their pain was the need to harness all of their enterprise data. So, for Striim, a platform that is able to ingest all this data, process it, produce results, and visualize it, the ability to work with what people already have, is vitally important.

Data Ingest
On the data ingestion side, the goal is to turn all sources of data into high velocity data streams. Message queues are already inherently streaming, but there’s lots of different flavors of these. There’s MQSeries (which goes back many years), and then there’s JMS, AMQP, Kafka, and Flume to name a few. Enterprises may have many of these that you need to integrate with – all with different APIs and different ways of working with them.
Sensors don’t really have many standards around them yet. They can communicate over lots of different protocols with many data formats. You may or may not have to do edge processing. There are some protocols gaining popularity, like MQTT for example, but you still have to worry about parsing the data content. Then there’s all of the proprietary gateways and other things you may have to integrate with.
If you want streaming data from log files, working with batches of files (after the files have been complete) doing log shipping isn’t very efficient. We built a way of doing a continual reading of files as new data is being written to them. There are a few tricks here. Depending on how things are being flushed, the files you may have are just a partial record. You need to make sure that you don’t throw it away because it doesn’t match your parsing rules, and wait until it’s complete before you try and process it. It’s not as easy as just reading what’s at the end of the file. You have to have a state machine reading the file to make sure you get a complete record. With our agents and our collection mechanism, you can read files in a parallel fashion. It will read at the end of the file as new data is written and stream it out, in real time.
The final thing with in-memory computing, and streaming analytics in general, are databases. Databases aren’t normally thought of as streaming – they are a record of what has happened rather than what is happening right now. If you look at most enterprise DBAs, they won’t allow you to run SQL against the production database. They may create a read-only replica for you, but you’re going to have to have the same resources as the original database, and that’s expensive.
What you can do is use Change Data Capture (CDC). If you run Change Data Capture against the database, you’ll see all of the operations that happen in a database as they occur. It’s a technology that listens to the transaction log of the database. As things happen in a database, the operations are written to a transaction log, CDC sees it, and now you have real-time events coming out to match the operations in the database. Every insert, update, and delete becomes an equivalent event and it happens with very low latency. You can see what’s happening in a database in real-time, and that’s a much better match for in-memory computing then running queries against the database. One of the issues with running snapshot queries, apart from being expensive to run against the production database, is you can miss things. Example: if someone went in and they change a value, and then they changed it back again five minutes later. If you’re running a snapshot every 10 minutes, you’re going to miss it. You won’t miss it with Change Data Capture.
The key thing is you want your data collection to move at a speed of the data.
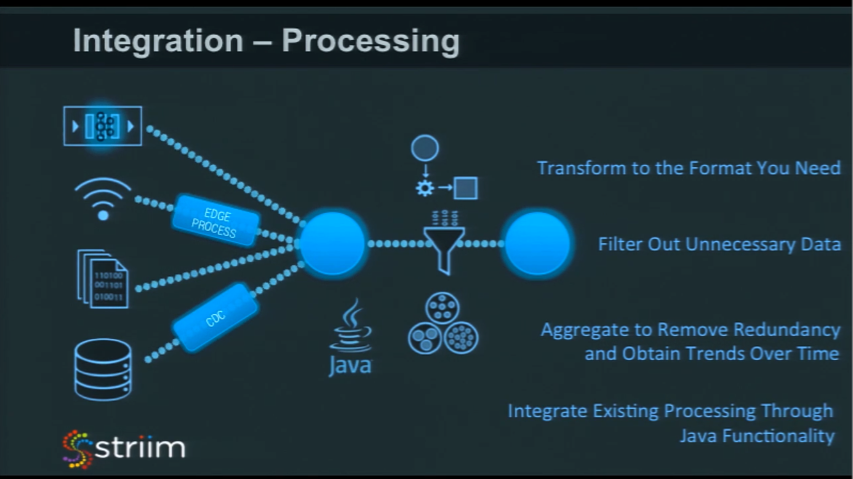
Processing
The next piece is what kind of processing you could do. There are different categories of things that you probably want to do in your in-memory computing platform. One is to filter out unnecessary data, transform the data into a form that you want, and read it. You may also wish to aggregate or look at portions of the data streams, and this is where windowing comes in – to aggregate and remove redundancy, or to identify trends over time.
Think about IoT. Imagine a thermostat, sending out a message (the temperature) of 72 degrees once per second. In an hour, you’ve got over three and a half thousand messages. If it stayed at 72 degrees that whole time, how much information is that? All of the data points result in just once piece of information – ’72 degrees for one hour’. You don’t need those three and a half thousand messages, so think about aggregation to remove redundancy and to look for trends over time.
An important part of integration is also being able to integrate with existing functionality. If you have Java code that’s being written already, or models built in R, or SaaS, and you want to use those models in-memory, you need to be able to integrate with those. You need to integrate existing models and existing processing into your in-memory computing platform.
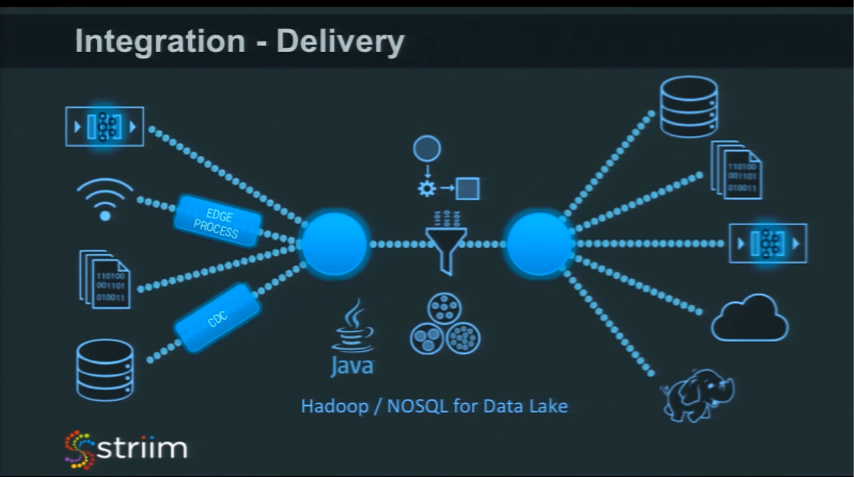
Delivery
You also have to consider the delivery side. Like sources, you need to think about all the different types of things you may want to deliver to. They all have different characteristics and different ways to work with them. Some of them are transactional (databases), some of them are on-premise, and some of them are in the cloud. With some, you need to think about data partitioning, like when delivering to Hadoop.
There’s different technologies and different approaches that you can take with each one, but they all have to work well with the security, reliability, and scalability that has been defined in this blog series. There are different tricks needed for each one of these different technologies.
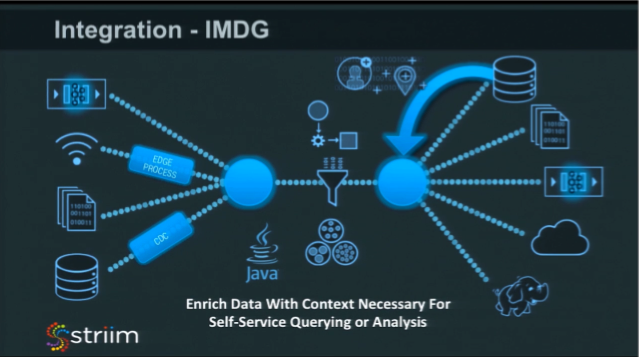
IMDG
Another integration area is to load large amounts of data into memory for the purpose of enrichment. What we’ve seen is a lot of raw streaming data that doesn’t have sufficient context to actually run queries or analysis against it. Example: in the telco space, there are call detail records – a record of every call that happened, what the signal strength was, whether the call was successful or not, where it was, etc. Within that record, there’s a whole bunch of hex codes that represent different things. One of those hex codes might be the serial number of the phone. Another might be your subscriber identifier. If you try running analytics on that, you’re not going to get a lot of information because of the hex codes.
One of our customers loaded about 40 million customer records into memory. As the data is flowing through, they join high-speed streaming data with their customer records using the subscriber identifier. Now the data is enriched with the customer information so that they can make decisions at a customer level, such as handling issues differently based on a customer’s service level.
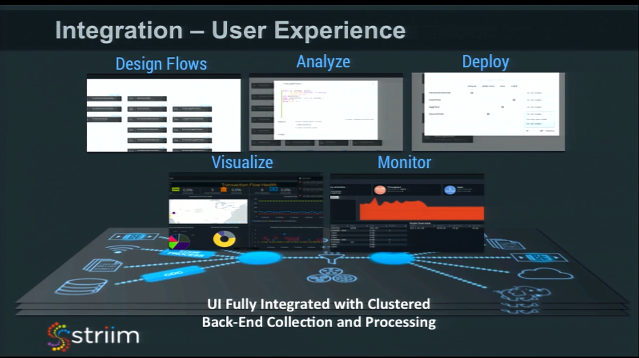
User Experience
If you are building an enterprise software platform that you really want people to use, then user experience is really important. If you have all this capability, ability to define data flows, analysis, and visualize results in dashboards, then you need to have a common user experience that hides the complexities of the in-memory computing platform from the end-user, without removing any capabilities for power users.
Multiple Common Use Cases
This kind of technology can be applied to many different use cases. It can be as simple as collecting database change and moving it into Hadoop, or pushing it into Kafka in real time. But the use cases can also be incredibly complex, like preventing fraud or unusual activity, or enhancing customer experience. As soon as you start to move into mission critical uses, the enterprise-grade characteristics really come in. If you are running fraud analytics, you want to make sure that’s working, it’s scalable, and is not going to fail.
To recap, this six-part blog series on making In-Memory Computing Enterprise Grade provided an overview, the overall data architecture, scalability, reliability, security and integration (this post). To learn more and chat with me directly, please register for my Weekly CTO Webinar!
![]()




