










Apache Kafka has proven itself as a fast, scalable, fault-tolerant messaging system, chosen by many leading organizations as the standard for moving data around in a reliable way.
However, Kafka was created by developers, for developers. This means that you’ll need a team of developers to build, deploy, and maintain any stream processing or analytics applications that use Kafka.
Striim is designed to make it easy to get the most out of Kafka, so you can create business solutions without writing Java code. Striim simplifies and enhances Kafka stream processing by providing:
- Continuous ingestion into Kafka and a range of other targets from a wide variety of sources (including Kafka) via built-in connectors
- UI for data formatting
- In-memory, SQL-based stream processing for Kafka
- Multi-thread delivery for better performance
- Enterprise-grade Kafka applications with built-in high availability, scalability, recovery, failover, security, and exactly-once processing guarantees
5 Key Areas Where Striim Simplifies and Enhances Kafka Stream Processing
1. Ingestion from a wide range of data sources with Change Data Capture support
Striim has over 150 out-of-the-box connectors to ingest real-time data from a variety of sources, including databases, files, message queues, and devices. It also provides wizards to automate developing data flows between popular sources to Kafka. These sources include MySQL, Oracle, SQL Server, and others. Striim can also read from Kafka as a source.
Striim uses change data capture (CDC) — a modern replication mechanism — to track changes from a database for Kafka. This can help Kafka to receive real-time updates of database operations (e.g., inserts, updates).
2. UI for data formatting
Kafka handles data at the byte level, so it doesn’t know the data format. However, Kafka consumers have varying requirements. They want data in JSON, structured XML, delimited data (e.g., CSVs), plain text, or other formats. Striim provides a UI — known as Flow Designer — that includes a drop-down menu, that lets users customize data formats. This way, you don’t have to do any coding for data formatting.
3. TQL for flexible and fast in-memory queries
Once data has landed in Kafka, enterprises want to derive value out of that data. In 2014, Striim introduced its streaming SQL engine, TQL (Tungsten Query Language) for data engineers and business analysts to write SQL-style declarative queries over streaming data including data in Kafka topics. Users can access, manage, and manipulate data residing in Kafka with Striim’s TQL. In 2017, Confluent announced the release of KSQL, an open-source, streaming SQL engine that enables real-time data processing against Apache Kafka. However, there are some significant performance differences between TQL and KSQL.
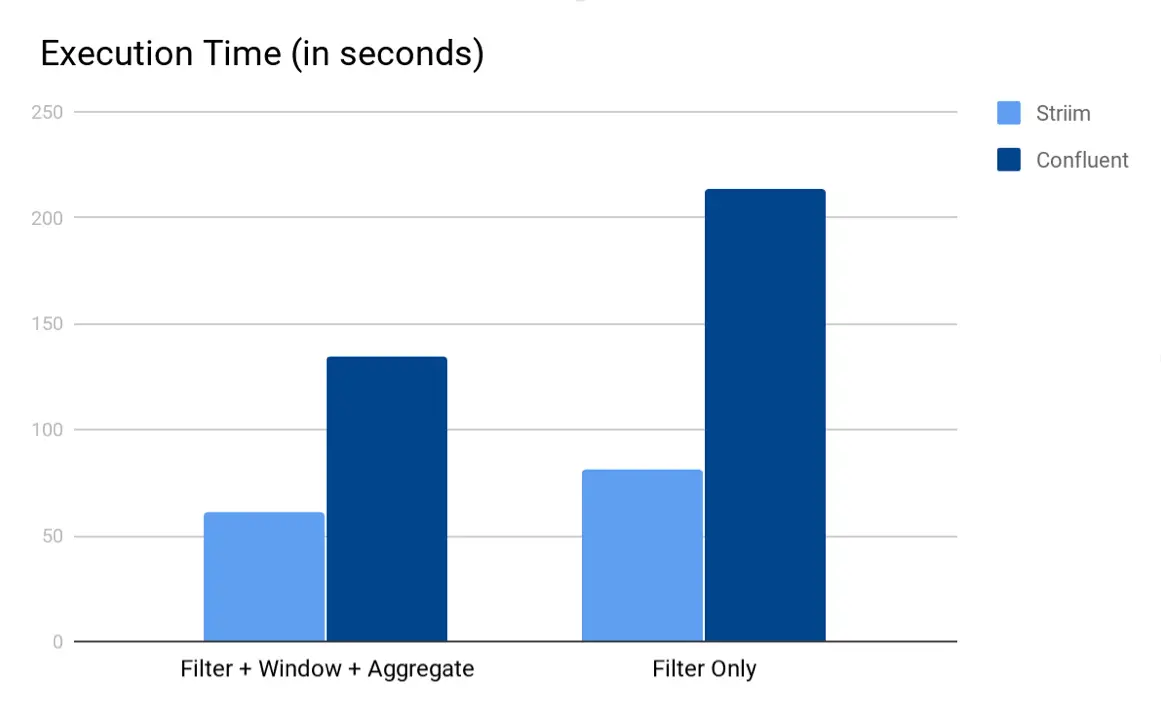
In a benchmarking study, TQL was observed to be 2–3 times faster than KSQL using the TCPH benchmark (as shown in the execution time chart above). This is because Striim’s computation pipeline can be run in memory, while KSQL relies on disk-based Kafka topics. In addition to speed, TQL offers additional features including:
- Windows: You cannot make attribute-based time windows with KSQL. It also doesn’t support writing multiple queries for the same window. TQL supports all forms of windows and lets you write multiple queries for the same window.
- Queries: KSQL comes with limited aggregate support, and you can’t use inner joins in it. Meanwhile, TQL supports all types of aggregate queries and joins (including inner join).
4. Multi-thread delivery for better performance
Striim has features that can improve performance while handling large amounts of data in real time. It uses multi-threaded delivery with automated thread management and data distribution. This is done through Kafka Writer in Striim, which can be used to write to topics in Kafka. When your target system struggles to keep up with incoming streams, you can use the Parallel Threads property in Kafka Writer to create multiple instances for better performance. This helps you to handle large volumes of data.
5. Support for mission-critical applications
Striim delivers built-in, exactly-once processing (E1P) in addition to the security, high availability and scalability required of an enterprise-grade solution. Using Striim’s Kafka Writer, if recovery is enabled, events are written in order with no duplicates (E1P). This means that in the event of cluster failure, Striim applications can be recovered with no loss of data.
Take Kafka to the Next Level: Try Striim
If you want to make the most of Kafka, you shouldn’t have to architect and build a massive infrastructure, nor should you need an army of developers to craft your required processing and analytics. Striim enables Data Scientists, Business Analysts and other IT and data professionals to get the most value out of Kafka without having to learn, and code to APIs.
See for yourself how Striim can help you take Kafka to the next level. Start a free trial today!




