










Businesses of all scales and industries have access to increasingly large amounts of data, which need to be harnessed effectively. According to an IDG Market Pulse survey, companies collect data from 400 sources on average. Companies that can’t process and analyze it to glean useful insights for their operations are falling behind.
Thousands of companies are centralizing their analytics and applications on the AWS ecosystem. However, fragmented data can slow down the delivery of great product experiences and internal operations.
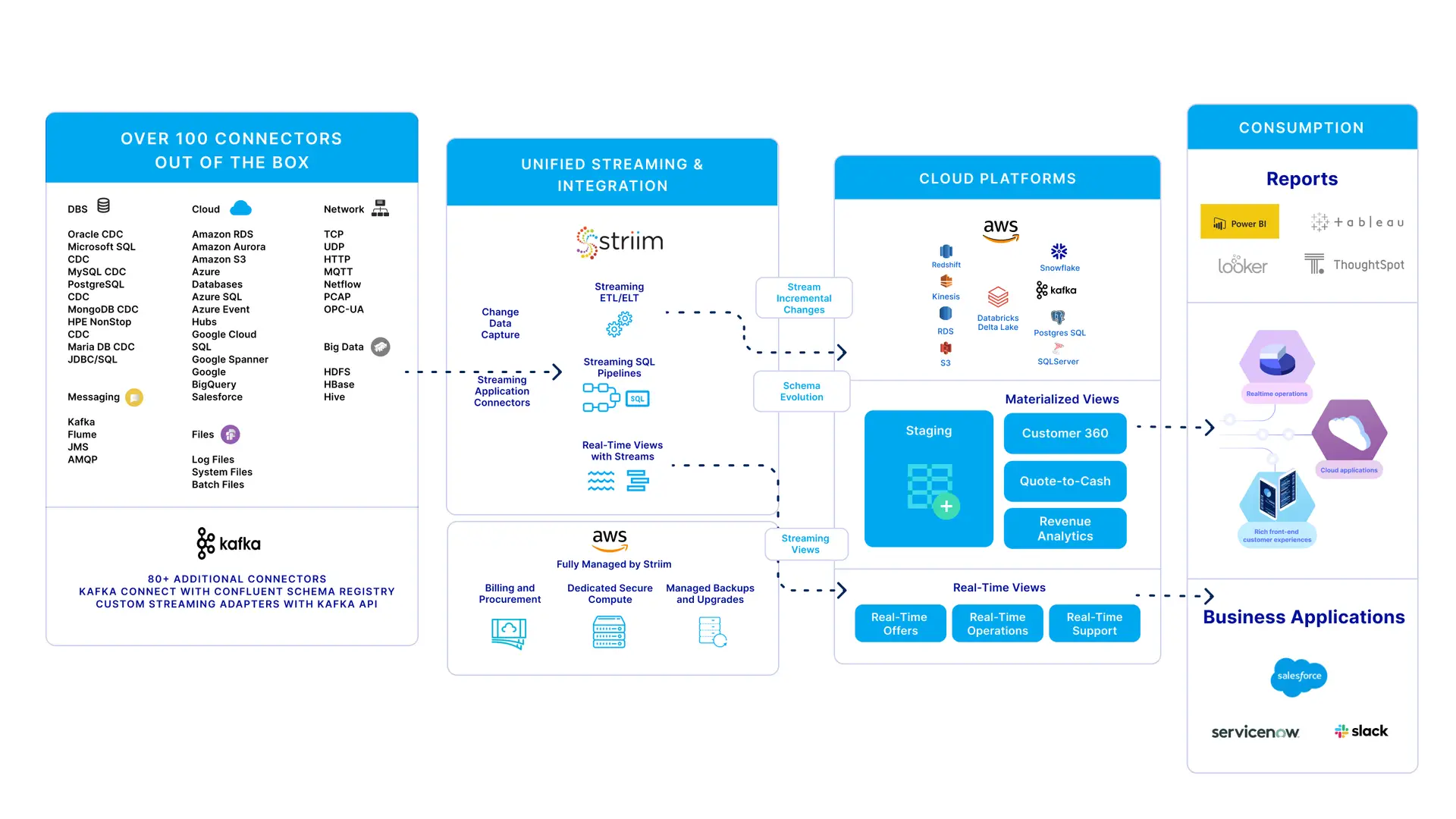
We are excited to launch Striim Cloud on AWS: a real-time data integration and streaming platform that connects clouds, data and applications with unprecedented speed and simplicity.
With a serverless experience to build smart data pipelines in minutes, Striim Cloud on AWS helps you unify your data in real time with out-of-the box support for the following targets:
- AWS S3
- AWS Databases on RDS and Aurora
- AWS Kinesis
- AWS Redshift
- AWS MSK
- Snowflake
- Databricks with Delta Lake on S3
along with over 100 additional connectors available at your fingertips as a fully managed service.
Striim Cloud runs natively on AWS services like EKS, VPC, EBS, Cloudwatch, and S3 enabling it to offer infinite large-scale, high performance, and reliable data streaming.
How does Striim Cloud bring value to the AWS ecosystem?
Striim enables you to ingest and process real-time data from over one hundred streaming sources. This includes enterprise databases via Change Data Capture, transactional data, and AWS Cloud environments. When you run Striim on AWS, it lets you create real-time data pipelines for Redshift, S3, Kinesis, Databricks, Snowflake and RDS for enterprise workloads.
Sources and targets
Striim supports more than 120+ sources and targets. It comes with pre-built data connectors that can automate your data movement from any source to AWS Redshift or S3 within a few minutes.
With Striim, all your team needs to do is to hit a few clicks for configuration, and an automated pipeline will be created between your source and AWS targets. Some of the sources Striim supports include:
- Databases: Oracle, Microsoft SQL Server, MySQL, PostgreSQL, etc.
- Data Streams: Kafka, JMS, IBM MQ, Rabbit MQ, IoT data over MQTT
- Data formats: JSON, XML, Parquet, Free Form Text, CSV, and XML
- AWS targets: RDS for Oracle, RDS for MySQL, RDS for SQL Server, Amazon S3, Databricks via Delta Lake on S3, Snowflake, Redshift, and Kinesis
- Additional targets: Over 100 additional connectors including custom Kafka endpoints with Striim’s full-blown schema registry support
Change data capture
Change data capture (CDC) is a process in ETL used to track changes to data in databases (e.g., insert, update, delete) and stream those changes to target systems like Redshift. However, CDC approaches like trigger-based CDC or timestamps can affect the performance of the source system.
Striim supports the latest form of CDC — log-based CDC — which can reduce overhead on source systems by retrieving transaction logs from databases. It also helps move data continuously in real time in a non-intrusive manner. Learn about log-based CDC in detail here.
Streaming SQL
Standard SQL can only work with bounded data that are stored in a system. While dealing with streaming data in Redshift, you can’t use standard SQL because you are dealing with unbounded data, i.e., data that keep coming in. Striim provides a Streaming SQL engine that helps your data engineers and business analysts write SQL-style declarative queries over streaming data. These queries never stop running and can continuously produce outputs as streams.
Data transformation and enrichment
Data transformation and enrichment are critical steps to creating operational data products in the form of tables and materialized views with minimal cost and duplication of data. To organize these data into a compatible format for the target system, Striim helps you perform data transformation with Streaming SQL. This can include operations such as joining, cleaning, correlating, filtering, and enriching. For example, enriching helps you to add context to your data (e.g., by adding geographical information to customer data to understand their behavior).
What makes Striim unique in this regard is that it not only supports data transformation for batch data, but it also supports in-flight transformations for real-time streams with a full blown Streaming SQL engine called Tungsten.
Use case: How can an apparel business analyze data with Striim?
Suppose there’s a hypothetical company, Acme Corporation, which sells apparel across the country. The management wants to make timely business decisions that can help them to increase sales and minimize the number of lost opportunities due to delays in decision-making. Some of the questions that can help them to make the right decisions include the following:
- Which product is trending at the moment?
- Which store and location received the highest traffic last month?
- What’s the inventory status across warehouses?
Currently, all store data is stored in a transaction database (Oracle). Imagine you’re Acme Corporation’s data architect. You can generate and visualize answers to the above questions by building a data pipeline in two steps:
- Use Striim Cloud Enterprise to stream data from Oracle to Amazon Redshift.
- After data is loaded into Redshift, use Amazon QuickSight service to show data insights and create dashboards.
Here’s how the flow will look:
In this blog, we will show you how you can configure and manage Striim Cloud Enterprise on AWS to create this pipeline for your apparel business within a few minutes.
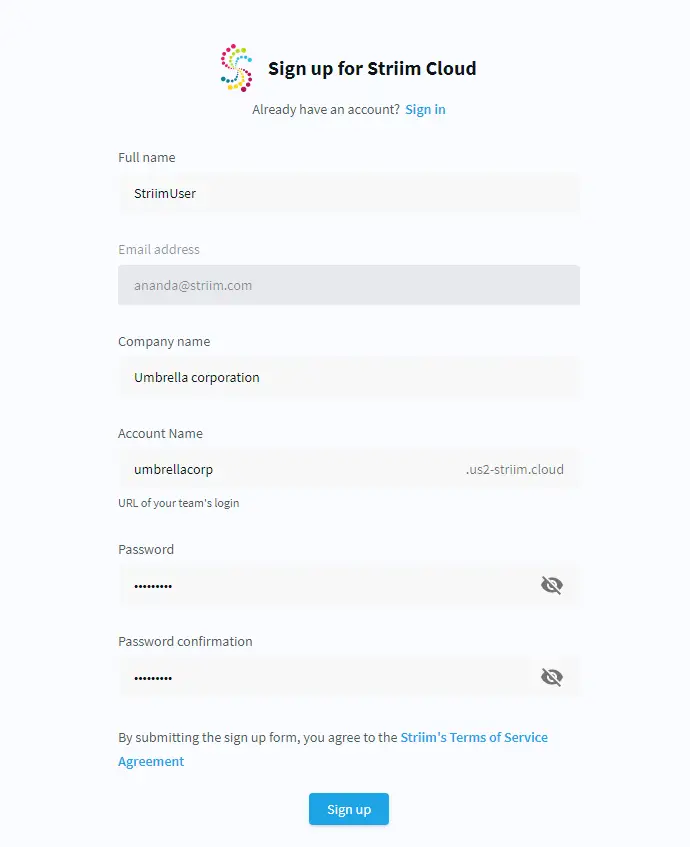
Sign up for Striim Cloud
Signing up for Striim Cloud Enterprise is simple: just visit striim.com, get a free trial and sign up for the AWS solution. Activate your account by following the instructions.
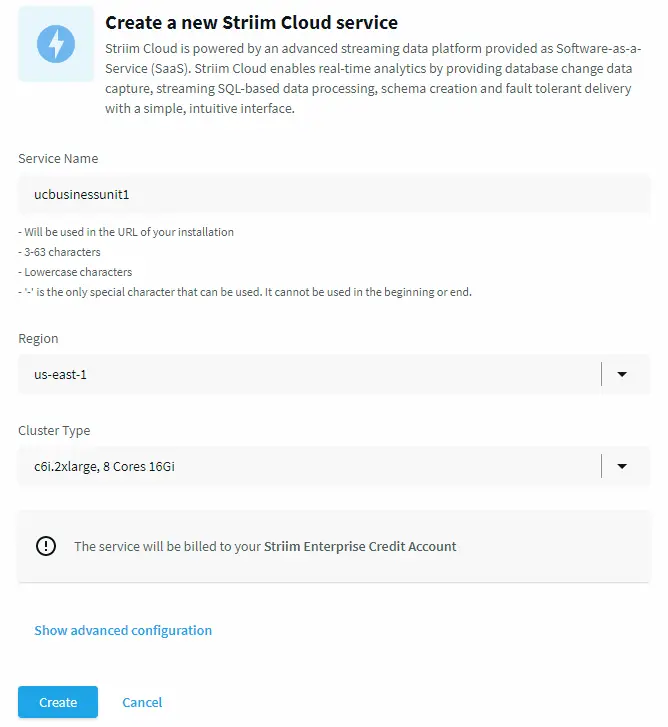
Once you are signed in, create a Striim Cloud service, which essentially runs in the background and creates a dedicated Kubernetes cluster (EKS service on AWS) to host your pipeline, as you can see in the picture below.
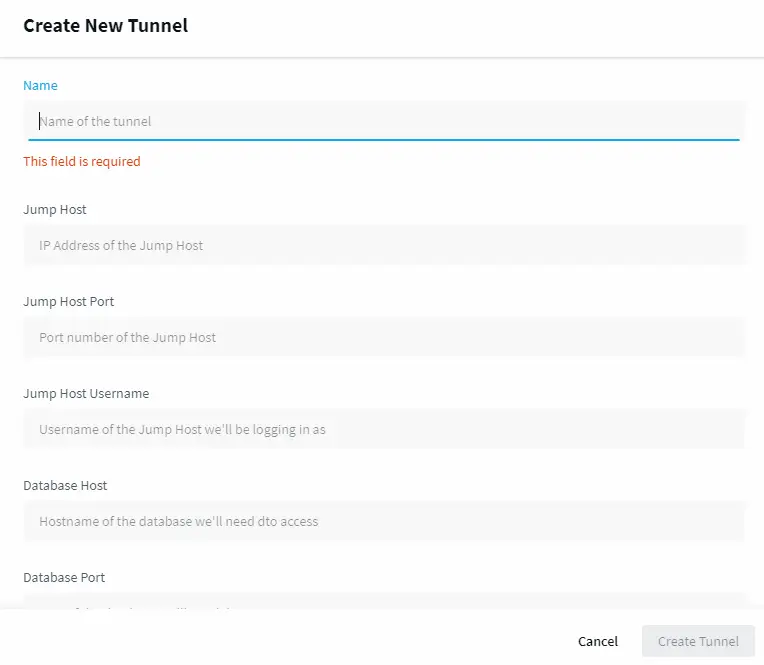
Once the cluster is ready and before launching your service, configure secure connections using the secure SSH connection configuration, as seen below.
Create a pipeline for Oracle to Amazon Redshift
To create a pipeline, simply type Source: Oracle and target Amazon to see all the supported targets. In our example, we are selecting Amazon S3 as our target. This could be Amazon Redshift, Kinesis, etc.
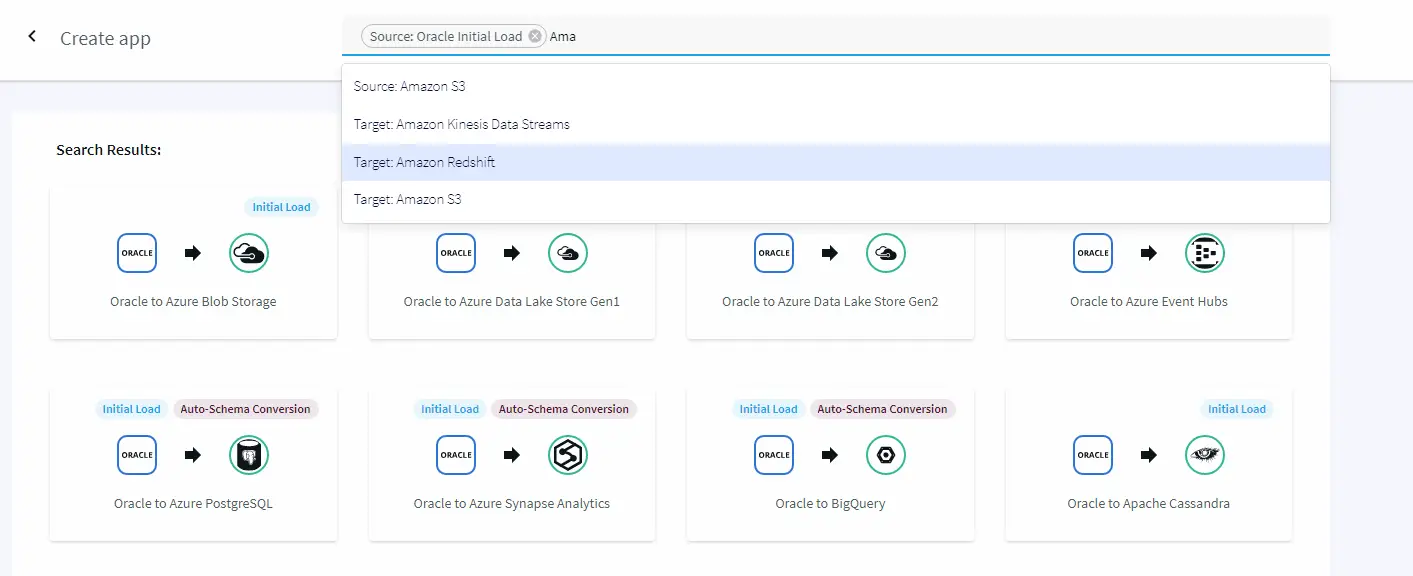
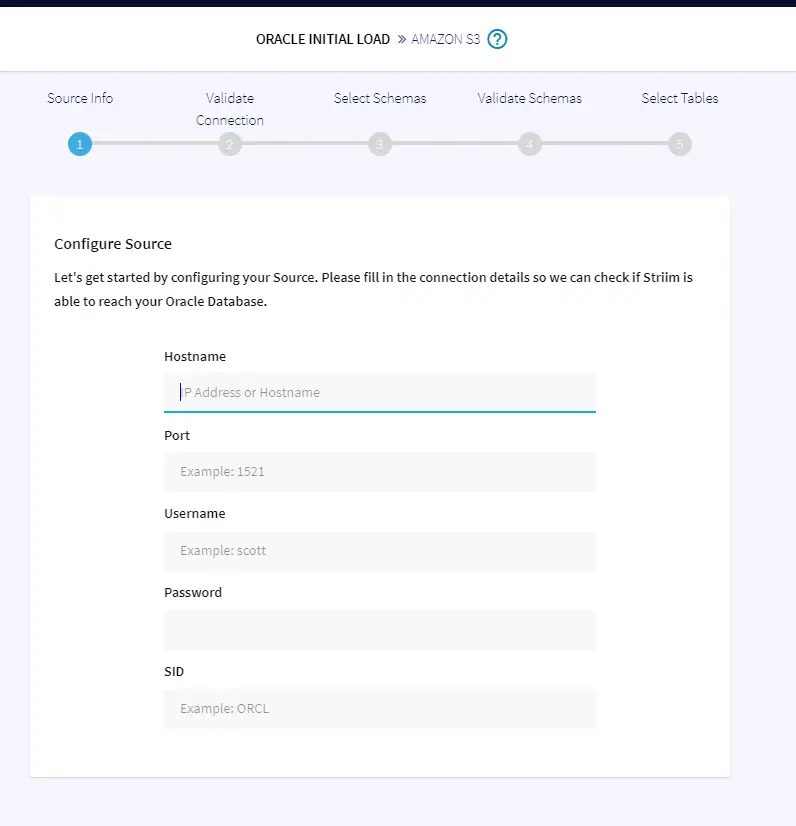
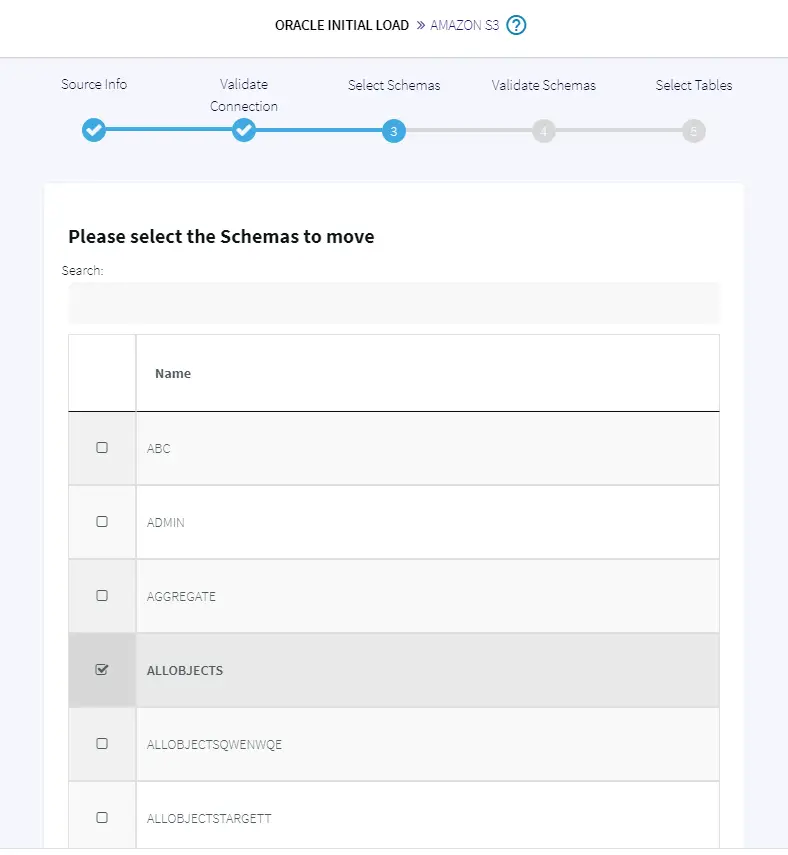
The wizard will help you walk through the simple process with source and target credentials. The service automatically validates the credentials, connects to the sources, and fetches the list of schemas and tables available on the sources for your selection, as shown below.
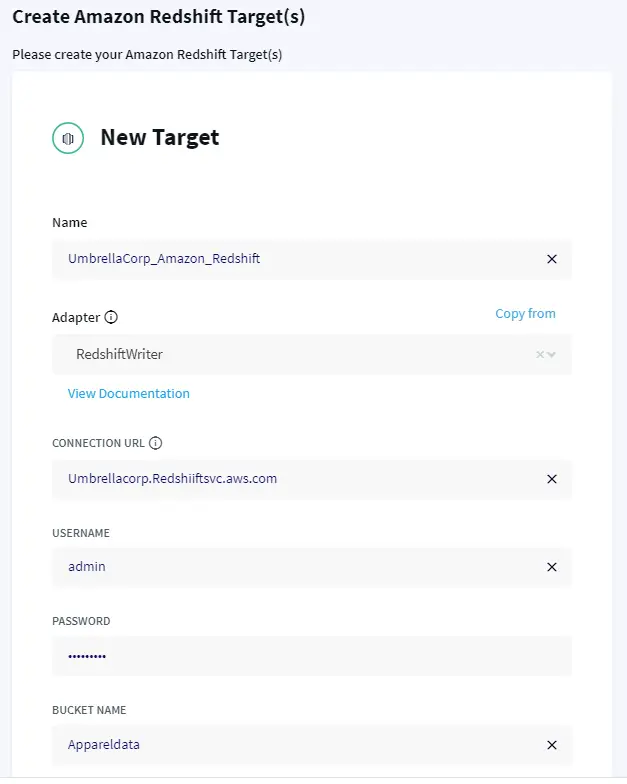
On the target side, enter Amazon Redshift Access Key and secret key with the appropriate S3 bucket name and Object names to write Oracle data into, as depicted in the image below.
Follow the wizard to finish the configuration, which creates a data pipeline that collects historical data from the Oracle database and moves them to Amazon Redshift. For example, you can see the total number of sales across all branches during the last week.
In the next step, you can create an Oracle CDC pipeline via Striim to stream real-time change data coming in from different stores into Oracle to Redshift. Now, you can see real-time store data.
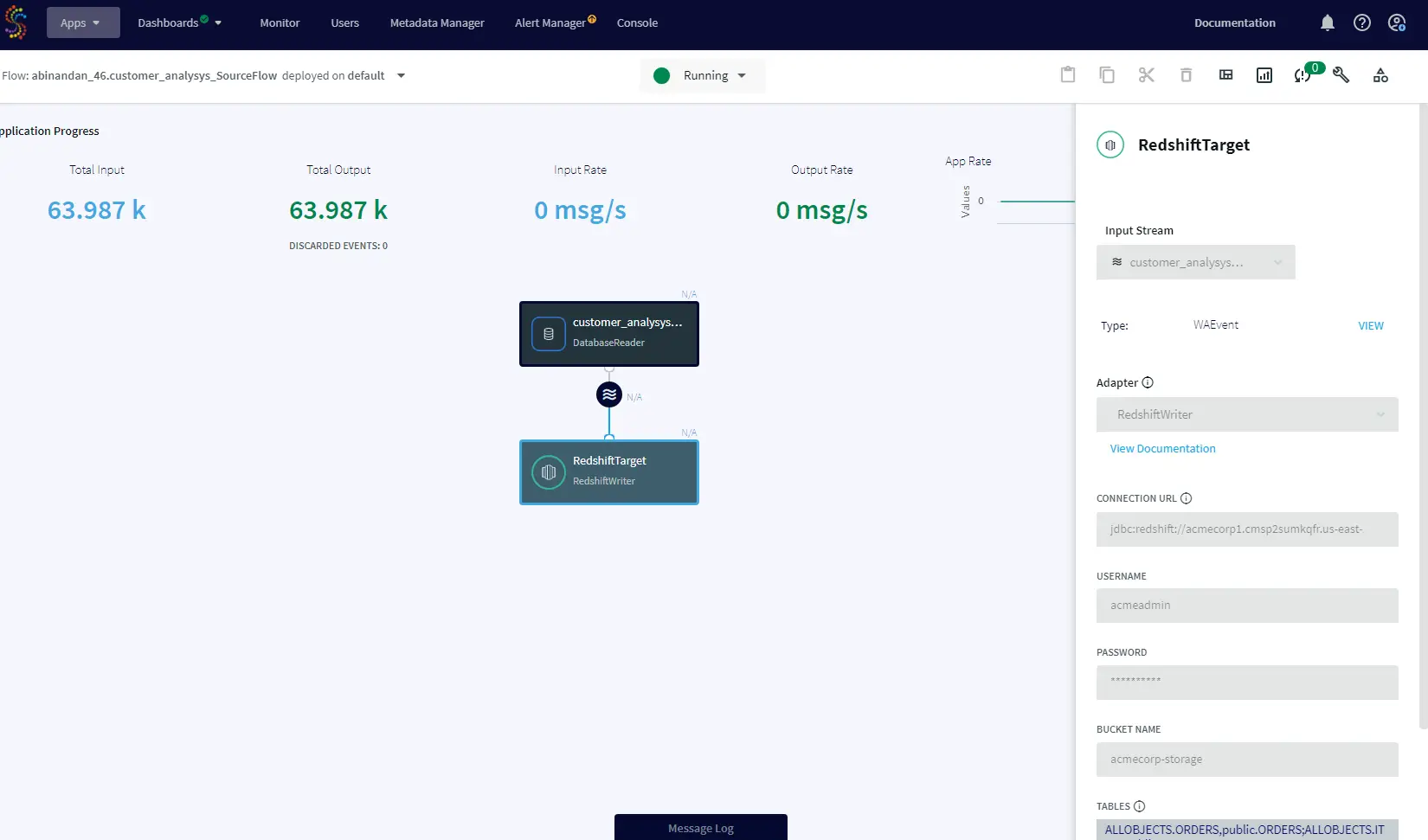
A data pipeline streaming data from the source (Oracle) to Amazon RedShift
Your data engineers can use streaming SQL to join, filter, cleanse, and enrich data on the real-time data stream before it’s written to the target system (S3). A monitoring feature offers real-time stream views for further low-latency insights.
Once data becomes available on Redshift, your data engineer can create dashboards and set up metrics for the relevant business use cases such as:
- Current product trending
- Store and location with the highest traffic last month
- Inventory status dashboard across warehouses; quantity sold by apparel, historic graph vs. latest (last 24 hours)
Data like current trending products can be easily shared with management for real-time decision-making and the creation of business strategies.
For example, here’s a real-time view of the apparel trends by city:
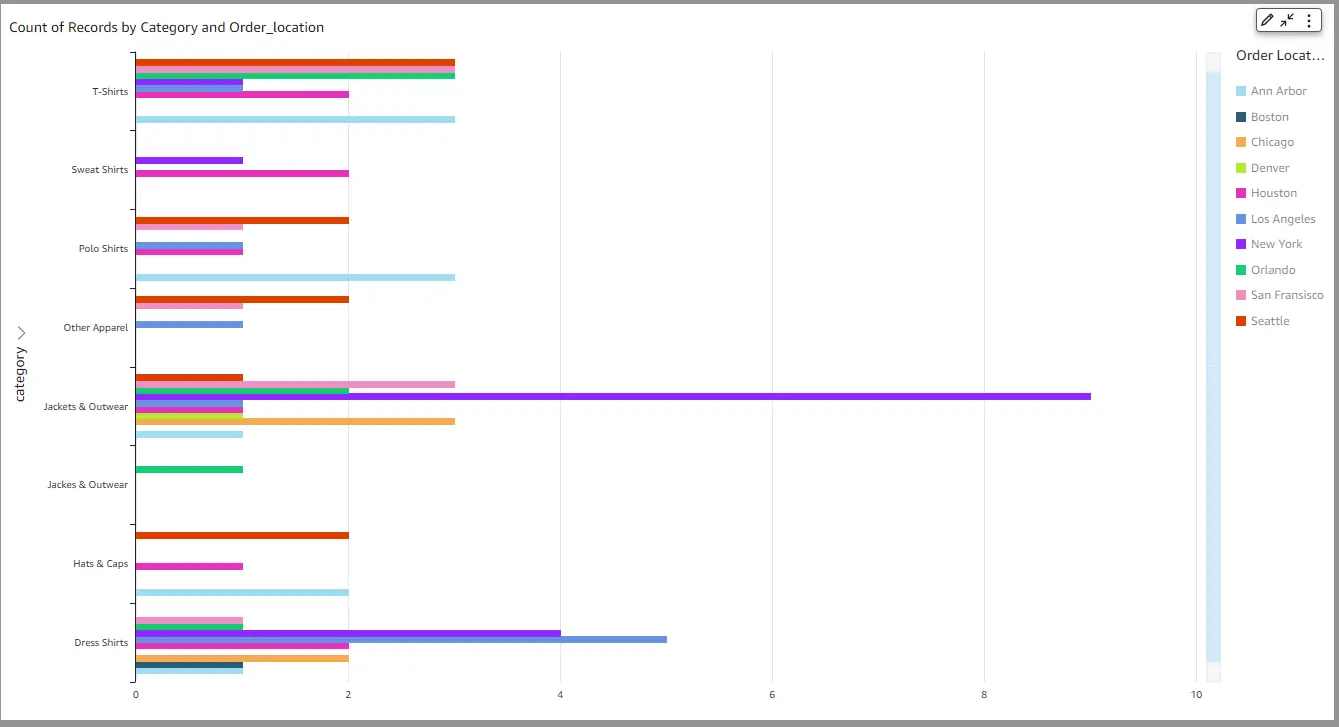
And below are insights on the overall business, where you can see the top-selling and bottom-selling locations. The management can use this information to try out new strategies to increase sales in the bottom-selling locations, such as by introducing discounts or running a more aggressive social media campaign in those locations.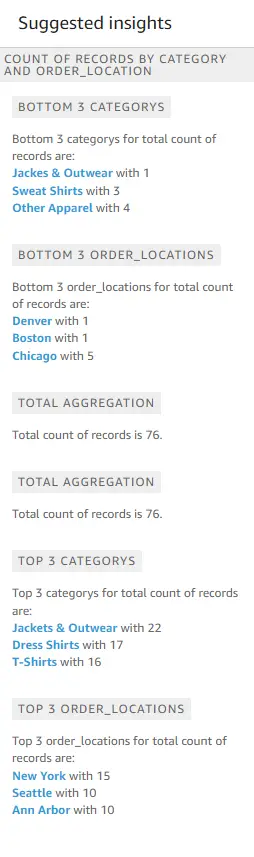
Striim is available for other cloud environments, too
Like AWS, Striim Cloud is available on other leading cloud ecosystems like Google Cloud and Microsoft Azure. You can use Striim with Azure to move data between on-premises and cloud enterprise sources while using Azure analytics tools like Power BI and Synapse. Similarly, you can use Striim with Google Cloud to move real-time data to analytics systems, such as Google BigQuery, without putting any significant load on your data sources.
Learn more about them here and here.




