Enterprises are drowning in data, but how much of it is arriving in time to deliver impact? Too often, critical decisions are held hostage by yesterday’s reports. Slow data is holding companies back.
The problem lies in infrastructure: brittle, batch-based pipelines that introduce costly delays and leave AI and analytics initiatives starved for relevant context. This isn’t just a technical frustration, it’s a barrier to competing in an economy that runs in real time.
It’s time to close the gap between data creation and data action. This guide breaks down how real-time data processing works, why it matters now more than ever, and the practical steps to implement it.
What Is Real-Time Data Processing?
Real-time data processing isn’t just about making batch jobs faster. It’s a fundamentally different approach: the practice of capturing, transforming, and acting on data the instant it’s created. Instead of collecting data in batches for later, real-time systems handle a continuous, event-driven flow of information with sub-second latency.
This distinction is significant. While batch processing delivers a static snapshot of the past, real-time processing provides a live, dynamic view of the present. It’s the difference between reviewing last week’s sales figures and instantly:
- Detecting a fraudulent transaction as it occurs.
- Adjusting inventory the moment an item sells.
- Personalizing a customer offer while they are still on your website.
For any organization that relies on up-to-the-minute information, real-time isn’t an upgrade, it’s a necessity.
Use Cases for Real-Time Data Processing
Across every industry, organizations use real-time data processing to drive measurable outcomes, from faster, data-informed decisions to hyper-personalized customer experiences. Here’s how it looks in practice:
Retail: Dynamic Pricing and Inventory Optimization
Real-time processing allows e-commerce and brick-and-mortar retailers to update pricing instantly based on competitor activity, demand shifts, or stock levels. It also provides an up-to-the-second view of inventory, preventing stockouts and improving the customer experience. Striim enables this with low-latency data delivery to apps and dashboards, enriched in-flight with contextual information like store location or user data.
Financial Services: Fraud Detection and Compliance
In an industry where every second counts, real-time streaming helps financial institutions detect anomalies and flag fraudulent transactions the moment they occur, not after the money is gone. This requires exceptional data consistency and auditability. Striim supports this with continuous monitoring and event stream correlation across multiple sources, ensuring fraudulent patterns are caught instantly.
Manufacturing & IoT: Predictive Maintenance and Telemetry
Sensor data from factory floors and IoT devices can be processed in real time to predict equipment failures before they cause costly downtime. By analyzing live telemetry, manufacturers can optimize asset performance and shift from reactive repairs to proactive maintenance. Striim makes this possible by enabling high-throughput data streaming from edge devices to cloud platforms for centralized intelligence.
Logistics: Real-Time Tracking and Route Optimization
GPS and shipment data can be used to dynamically update delivery routes, optimize fuel consumption, and provide customers with accurate ETAs. Real-time visibility is key to meeting SLAs and improving logistical efficiency. Striim’s support for multi-cloud and hybrid deployments ensures that data can be processed and routed effectively across distributed systems and geographies.
Feeding Real-Time Context to Intelligent Systems
As AI initiatives move from experiments to production, it creates massive demand for continuous, feature-rich data context. Real-time data pipelines enable low-latency inference for smarter recommendations, more accurate demand forecasting, and adaptive fraud models. Striim feeds these models with fresh, transformed data from enterprise sources, delivering it to warehouses, data lakes, or AI pipelines with minimal latency.
How Does Real-Time Data Processing Work?
Real-time data processing is a constant, iterative process, not a one-time event. It involves seamlessly orchestrating multiple steps to capture, enrich, and deliver fresh, actionable data the moment it’s needed. While architectures vary, the core workflow follows a clear path from source to target.
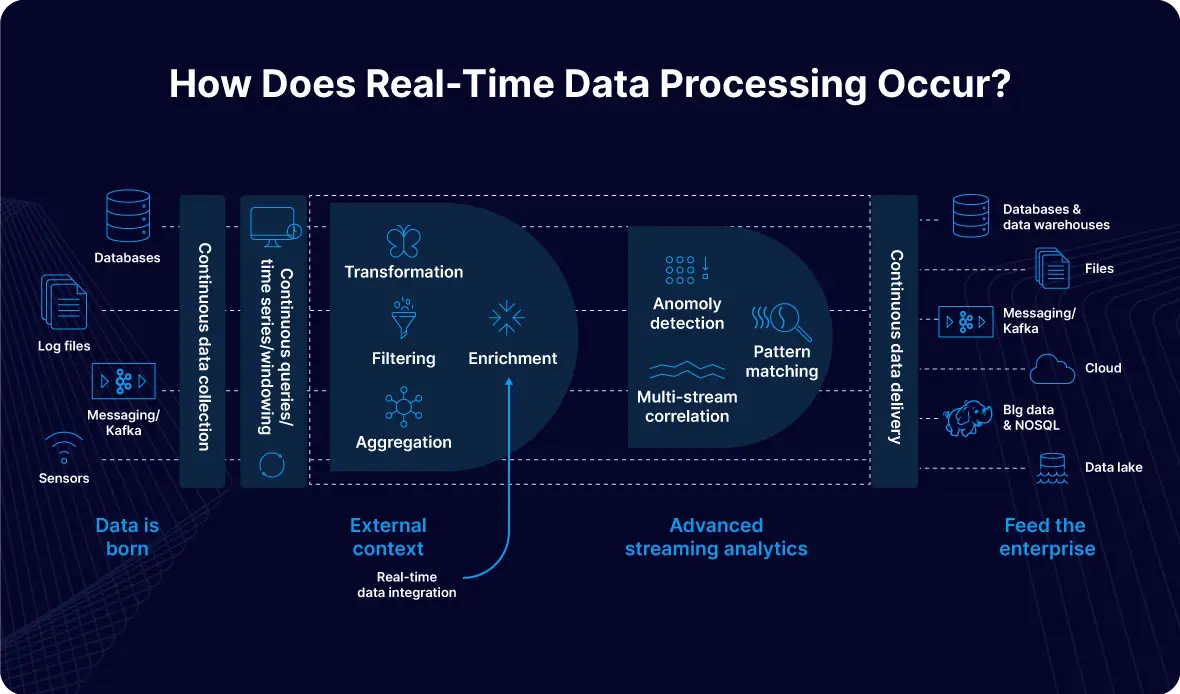
Step 1: Capture and Ingest Data as It’s Created
Every real-time pipeline begins at the source: databases, applications, message queues, IoT sensors, or log files. The key is to capture events as they happen with minimal latency. Low-impact methods like Change Data Capture (CDC) are ideal, as they read directly from database transaction logs without adding overhead. Striim excels here, offering high-throughput, schema-aware ingestion from hundreds of sources with zero disruption.
Step 2: Stream Data Into a Processing Engine
Once captured, data flows as an event stream into a processing engine designed for continuous computation. This is where concepts like windowing become critical for analysis, such as tumbling windows for periodic reports or sliding windows for moving averages. Striim’s architecture maintains a distributed in-memory state across active-active nodes to ensure calculations are executed consistently, eliminating the “split-brain” risk and allowing for dynamic scaling while keeping latency predictable.
Step 3: Filter, Enrich, and Transform in Flight
Raw data is rarely useful in its original state. In a real-time pipeline, value is added in-flight by filtering out irrelevant events, joining data with lookup tables, or applying business rules. Striim’s in-flight SQL-based processing engine simplifies this complex task. Its schema evolution engine also automatically detects and propagates source changes (like new columns) from CDC logs downstream without requiring a pipeline restart, avoiding the downtime that plagues many open-source stacks.
Step 4: Deliver to Targets with Sub-Second Latency
After processing, the enriched data must be delivered to its destination: a data warehouse, real-time application, or API. This final handoff must be fast and reliable. Striim provides native, optimized connectors to dozens of targets like Snowflake, Databricks, and Kafka, supporting parallel, region-aware delivery. Key features include:
- Exactly-once delivery semantics
- Built-in retries for transient failures
- In-transit TLS 1.3 encryption
Step 5: Monitor, Scale, and Optimize Continuously
Real-time data pipelines are dynamic systems that require constant observability to track latency, throughput, and potential bottlenecks. This means having robust error handling, replay capabilities, and the ability to scale components dynamically. Striim provides built-in monitoring dashboards, real-time metrics, and configurable alerting to keep pipelines healthy and give operators the visibility needed to optimize performance.
Tools and Technology for Real-Time Data Processing
Building a real-time data architecture requires a stack of specialized tools. Some teams choose to assemble a fragmented mix of components, while others opt for a unified platform to accelerate development and simplify operations. The right choice depends on your team’s expertise, architectural needs, and business goals.
Data Ingestion and Streaming Platforms
Tools like Apache Kafka, Apache Pulsar, and Amazon Kinesis form the foundation of many real-time systems, acting as a message bus to decouple data producers from consumers. While powerful, they require significant engineering expertise to set up, manage, and integrate. Striim’s approach simplifies this by tightly coupling ingestion with its processing engine, enabling schema-aware CDC with immediate enrichment without needing to stage data in an external bus.
Stream Processing Engines
Tools like Apache Flink or Spark Structured Streaming are often used to handle real-time transformations and aggregations. These engines are key to modern data architectures but often come with a steep learning curve, requiring advanced engineering resources to manage custom code and state. Striim abstracts this complexity with a low-code, SQL-based engine that empowers teams to define sophisticated processing logic without deep streaming expertise.
Unified Real-Time Data Platforms
Unified platforms like Striim combine ingestion, real-time processing, enrichment, and delivery into a single, cohesive solution. This stream-first architecture reduces latency, simplifies pipeline management, and eliminates the operational overhead of managing multiple components. For teams that prioritize fast time-to-value, scalable operations, and end-to-end observability, a unified platform is the clear choice.
Best Practices for Real-Time Data Processing at Scale
Successfully implementing real-time data requires an architectural approach that prioritizes simplicity, observability, and low-latency data flow. As teams scale, they often encounter challenges with brittle pipelines and high maintenance overhead. The following best practices can make a difference.
Use Change Data Capture for Accurate, Low-Latency Ingestion
The quality of your pipeline depends on how you capture data at the source. Polling-based ingestion is often slow and places unnecessary strain on source systems. Instead, use Change Data Capture (CDC) to stream events directly from transaction logs. This ensures you get clean, accurate data with minimal latency.
Enrich, Filter, and Transform In-Flight
A stream-first architecture allows you to apply business logic and enrich data before it’s written to storage. This is a significant advantage over traditional approaches where transformations happen in separate batch layers. By processing data in-flight with a SQL-based engine like Striim, you can simplify your stack and deliver data that is immediately ready for consumption.
Monitor, Tune, and Test Your Pipelines Continuously
Distributed, event-driven systems require robust observability. Challenges like latency spikes and schema drift can be difficult to debug without the right tools. Adopt a platform that provides built-in visibility across the full pipeline, from ingestion to delivery, to make it easier to maintain, tune, and optimize your operations.
Transform Your Data Strategy with Striim
The gap between data creation and business action is shrinking. In an economy where speed is a competitive advantage, real-time data processing is no longer a niche capability. It’s a foundational requirement for building smarter, faster, and more responsive organizations.
Striim provides a unified, enterprise-grade platform that simplifies the complexity of real-time data processing. With low-latency change data capture, a powerful SQL-based stream processing engine, and seamless integration with your existing cloud and on-prem systems, Striim empowers you to turn your data into a strategic asset the moment it’s created.
Ready to see it in action? Book a demo with our experts or start your free trial today.


