










Delivering Kafka Data
In Part 2 of this blog series, we looked at how the Striim platform is able to continuously ingest data from a wide variety of data sources, including enterprise databases via change data capture (CDC), and process and deliver that data in real time into Apache Kafka. Here we’ll take a look at the other side of the equation – delivering Kafka data in real time to enterprise targets, including a wide range of Hadoop and cloud environments.
Delivering Kafka Data to Enterprise Targets
Kafka is not a destination. It may be you are using Kafka as the underpinning of stream processing and analytics, or as a data distribution hub. Whatever the use case, sooner or later you will want to deliver the Kafka data to somewhere else. As with sourcing data, this should not be difficult and should also not require coding.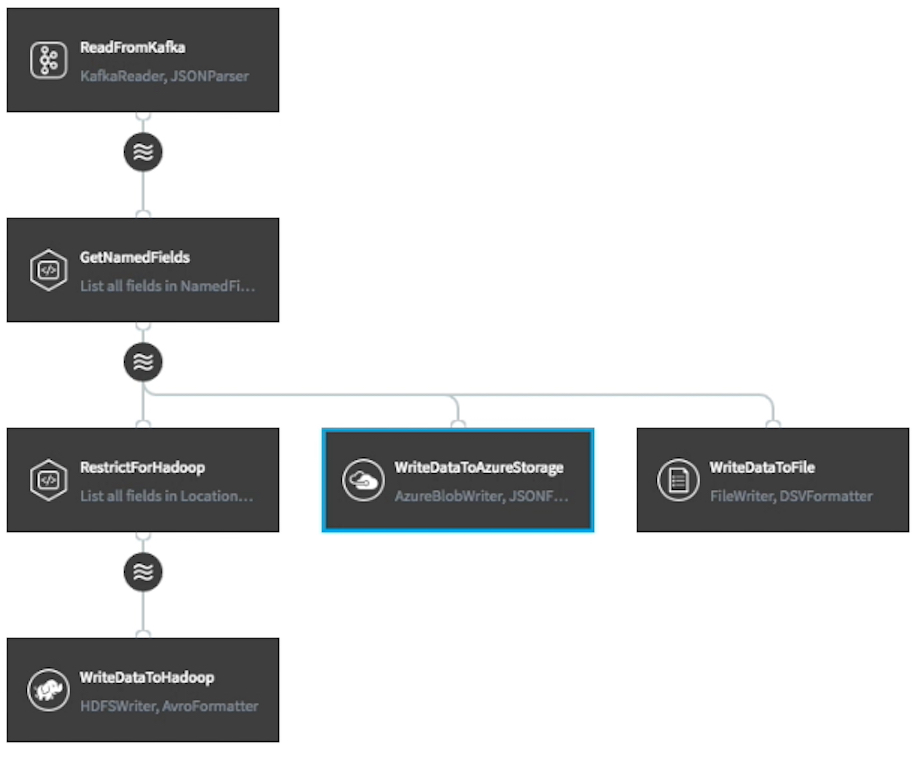
The Striim platform can write continuously to a broad range of data targets, including databases, files, message queues, Hadoop environments, and cloud data stores like blob storage, Azure SQL DB, Amazon Redshift, and Google BigQuery (to name just a few cloud targets that Striim supports). The written data format is again configurable and can be applied to the raw Kafka data, or to the results of processing and analytics. This is all achieved through the drag-and-drop UI or scripting language, and is simply a matter of choosing the target and configuring properties.
What’s more, a single data flow can write to multiple targets at the same time in real time, with rules encoded as queries in between. This means you can source data from Kafka and write some of it – or all of it – to HDFS, Azure SQL DB, and your enterprise data warehouse simultaneously.
For more information on Striim’s latest enhancements relating to Kafka, please read this week’s press release, “New Striim Release Further Bolsters SQL-based Streaming and Database Connectivity for Kafka.” Or download the Striim platform for Kafka and try it for yourself.
Continue reading this series with Part 4: “Making the Most of Apache Kafka,” – Data Processing and Preparation for Kafka.




