










In this Whiteboard Wednesday video, Irem Radzik, Head of Product Marketing at Striim, looks at how data movement technologies have evolved in response to changing user demands. Read on, or watch the 8-minute video:
Today we’re going to talk about the advancement of data movement technologies. We’re going to look at the ETL technologies that we started seeing in ‘90s, then the CDC (Change Data Capture)/Logical Replication solutions that we started seeing a couple of decades ago, and then streaming data integration solutions that we more commonly see today.
ETL
Let’s look at ETL technologies. ETL is known for its batch extract, then bringing the data into the transformation step in the middle tier server, and then loading the target in bulk again, typically for next-day reporting. You end up having high latency with these types of solutions. That was good enough for the ‘90s, but then we started demanding more fresh data for operational decision making. Latency became an issue with ETL solutions.
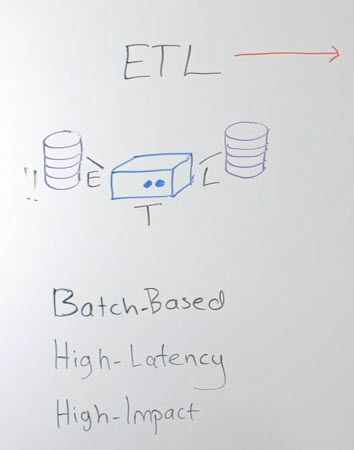
The other issue with ETL was the batch-window dependency. Because of the high impact on the production sources, there had to be a dedicated time for these batch extracts when the main users wouldn’t be able to use the production database. The batch window that was available for data extract became shorter and shorter as business demanded continuous access to the OLTP system.
The data volumes increased at the same time. You ended up not having enough time to move all the data you needed. That became a pain point for ETL users, driving them to look into other solutions.
Change Data Capture/Logical Replication
Change Data Capture/Logical Replication solutions addressed several of the key concerns that ETL had. Change Data Capture basically means that you continuously capture new transactions happening in the source database and deliver it to the target in real time.
 That obviously helps with the data latency problem. You end up having real-time, up to date data in the target for your operational decision making. The other plus of CDC is the source impact.
That obviously helps with the data latency problem. You end up having real-time, up to date data in the target for your operational decision making. The other plus of CDC is the source impact.
When it’s using logs (database logs) to capture the data, it has negligible impact. The source production system is available for transaction users. There is no batch window needed and no limitations for how much time you have to extract and move the data.
The CDC/Logical Replication solutions handle some of the key concerns of ETL users. They are made more for the E and L steps. What ends up happening with these solutions is that you need to do transformations within the database or with another tool, in order to complete the transformation step for end users.
The transformation happening there creates an E L T architecture and requires another product, another step, another network hub in your architecture, which complicates the process.
When there’s an outage, when there is a process disruption, reconciling your data and recovering becomes more complicated. That’s the shortcoming CDC users have been facing. These solutions were mainly made for databases.
Once the cloud and big data solutions became popular, the CDC providers had to come up with new products for cloud and big data targets. These are add-ons, not part of the main platform.
Another shortcoming that we’ve seen with CDC/Logical Replication solutions is their single node architecture, which translates into a single point of failure. This is a shortcoming, especially for mission-critical systems that need continuous availability of the data integration processes.
Streaming Data Integration
In recent years, streaming data integration came about to address the issues that CDC/Logical Replication products raised. It is becoming increasingly common. With streaming data integration, you’re not limited to just database sources.
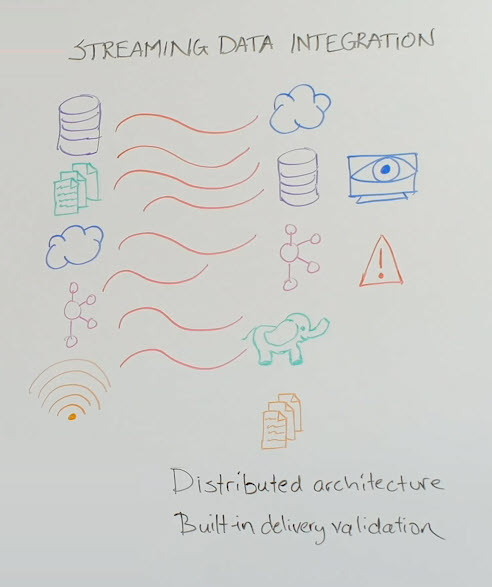 You can have your files, log data, your machine data, your system log files for example, all moving in a real-time fashion. Your cloud sources, your service bus or your messaging systems can be your source. Your sensor data can be moved in real time, in a streaming fashion to multiple targets. Again, not limited to just databases.
You can have your files, log data, your machine data, your system log files for example, all moving in a real-time fashion. Your cloud sources, your service bus or your messaging systems can be your source. Your sensor data can be moved in real time, in a streaming fashion to multiple targets. Again, not limited to just databases.
You can have cloud databases or other cloud services as your target. You can, in addition to databases, have messaging systems as your target, on-premises or in cloud, your big data solutions, on-premises or cloud. You can also deliver in file format.
Everything is like it was in a logical replication solution. It is continuous, in real time, and Change Data Capture is still a big component of the streaming data integration.
It’s built on top of the Change Data Capture technologies and brings additional data sources and additional data targets. Another important difference, and handling one of the challenges of logical replication, is the transformation piece. As we discussed, a transformation needs to happen and where it happens makes a big difference.
With streaming data integration, it’s happening in-flight. While the data is moving, you can have stream processing without adding more latency to your data. While the data is moving, it can be filtered, it can be aggregated, it can be masked and encrypted, and enriched with reference data, all in flight before it’s delivered to your target, so that it’s available in a consumable format. This streamlines your architecture, simplifies it, and makes all the recovery steps easier. It’s also delivering the data in the format that your users need.
Another important thing to highlight is the distributed architecture. This natively clustered environment helps with a single point of failure risk. When one node fails, the other one takes over immediately, so you have a highly available data pipeline. This distributed clustered environment also helps you to scale out very easily, add more servers as you have more data to process and move.
These solutions now come with a monitoring part. The real time monitoring of the pipelines gives you an understanding of what’s happening with your integration flows. If there is an issue, if there is high data latency or process issue, you get immediate alerts so you can trust that everything is running.
Data reliability is really critical, whole pipeline reliability is very critical. To make sure that there is no data loss or duplicates, there is data delivery validation that can be included in some of these solutions. You can also make sure, with the right solution, that everything is processed exactly once, and you are not repeating or dropping data. There are checkpointing mechanisms to be able to do that.
As you see, the new streaming data integration solutions handle some of the challenges that we have seen in the past with outdated data movement technologies. To learn more about streaming data integration, please visit our Real-time Data Integration solution page, schedule a demo with a Striim expert, or download the Striim platform to get started.




