










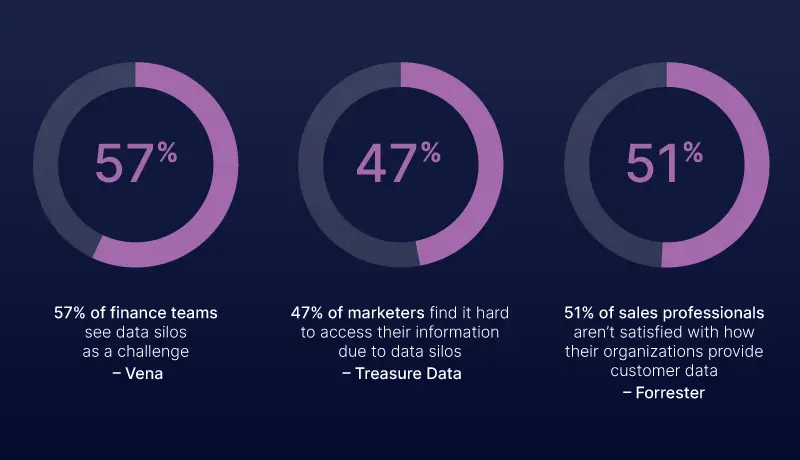
Consider the following stats: the 2020 Vena Industry Benchmark Report found that 57% of finance teams see data silos as a challenge; Treasure Data’s Customer Journey Report noted 47% of marketers find it hard to access their information due to data silos, and a Forrester study stated that 51% of sales professionals aren’t satisfied with how their organizations provide customer data. To sum up, non-technical users are struggling with data access. So, what’s causing these data silos?
Most organizations store their data in a data warehouse. Due to the inherent structure of the extract, transform, and load (ETL) process, this data is mainly used by data scientists, data engineers, and data analysts. These roles do their best to provide data to other non-data departments like customer success, sales, and marketing. However, these non-data departments need a better form of data access and analytical insights. That’s where reverse ETL can be a game-changer.
Reverse ETL is a new addition to the modern data ecosystem that can make organizations more data-driven. It empowers operational teams to get access to transformed data in their day-to-day business platforms, such as ERPs, CRMs, and MarTech tools.
Why Should You Adopt Reverse ETL?
Beat Your Competition with a Personalized Customer Experience
What Is ETL vs. Reverse ETL?
The ETL process takes data from a source, such as customer touchpoints (e.g., CRM), processes/transforms this data, then stores it at a target, which is usually a data warehouse. The reverse ETL does the opposite by swapping the source and destination, i.e., it takes data from the data warehouse and sends it to operational business platforms.
Another difference between ETL and reverse ETL is their approach to data transformations. With ETL, data engineers perform data transformation before loading data into a data warehouse. This data can be used by data scientists and data analysts who analyze it for different purposes, such as building reports and dashboards.
In reverse ETL, data engineers perform data transformation on the data in the data warehouse so that third-party tools can use it immediately. This data is used by marketers, sales professionals, customer success managers, and other non-data roles to make data-driven decisions.
For instance, your BI report shows cost per lead (CPL) data that you need to send to a CRM system. In that case, your data engineer has to perform data transformations via SQL in your data warehouse. This transformation isolates your CPL data, formats it for your on-site platform, and adds it into the CRM, so your marketing experts can use this data for their campaigns.
How Does Reverse ETL Work?
Reverse ETL solutions deliver real-time data to operational and business platforms (like Salesforce, Intercom, Zendesk, MailChimp, etc.). It is a process that turns your data warehouse into a data source and the operational and business platforms into a data destination. Making data readily available to these platforms can give your front-line teams a 360-degree view of customer data. They can use data-driven decision-making for personalized marketing campaigns, smart ad targeting, proactive customer feedback, and other use cases.

One might wonder: why are we moving the data back to those SaaS tools after moving data from them to data warehouses? That’s because sometimes, data warehouses can fail to address data silos.
Your key business metrics might be isolated in your data warehouse, limiting your non-data departments from making the most of your data. With traditional ETL, these departments are highly dependent on your data teams. They have to ask data analysts to send a report every time they need relevant insights. Likewise, once they add a new SaaS tool to their workflow, they rely on your data engineer to write custom API connectors. These issues can slow the speed of data access and availability for your front-line business users. Fortunately, reverse ETL can plug this gap.
Reverse ETL can help you to sync your KPIs (e.g., customer lifetime value) with your operational platforms. It ensures your departments can get real-time and accurate insights to pave the way for data-driven decision-making.
Why Should You Adopt Reverse ETL?
Reverse ETL solves a myriad of issues by democratizing data access, saving your data resources, and automating workflows.
It democratizes data beyond the data team
Reverse ETL enables data teams to channel data insights to other operational business teams in their usual workflow. Data becomes accessible and actionable because it is streamed directly from the data warehouse to platforms like CRMs, advertising, marketing automation, and customer support ticketing systems.
Providing more in-depth knowledge to the front-line team, such as your customer success team, can help your team members to make better decisions. It ensures that your front-line personnel are now equipped with comprehensive insights that can help them to personalize the customer experience. For instance, your data science team used complex modeling to segment your customer data, which is updated every week. Your customer success team can use reverse ETL to import this data automatically to an email platform and send personalized emails.
It reduces the engineering burden on data engineers
Traditionally, data engineers will have to build API connectors to channel data from the data warehouse to the operational business platforms. These API connectors come with a myriad of challenges, which include:
- Writing APIs and maintaining them is challenging for data engineers.
- It can take a few days to map fields from a source of truth (e.g.,data lake) to a SaaS app.
- Often, these APIs are unable to process real-time data transfer.
Reverse ETL is designed to address these challenges. For starters, these reverse ETL tools come with built-in connectors. For this reason, data teams don’t have to write API connectors and maintain them. Previously, data teams might have only written a limited number of connectors. However, reverse ETL’s out-of-the-box connectors mean that companies can send data into more systems now.
Moreover, ETL tools consist of a visual interface that allows you to populate SaaS fields automatically. Reverse ETL tools can help you to define what triggers the movement of data between your data warehouse and operational business platforms to move data in real time.
As a result, you can save your data engineers’ time, and they can now turn their focus to other pressing data issues.
It automates and distributes data flow across multiple apps
Reverse ETL eliminates the manual process of switching between apps to get information. Reverse ETL feeds relevant KPIs and metrics to the operational systems at a pre-established frequency. This way, it can automate a number of workflows.
For instance, consider that your sales team uses Zendesk Sell as a CRM. One of the things that they do manually is to track freemium accounts and look for ways to turn them into paid users. For this purpose, your account managers need to jump back and forth between BI and CRM tools to view where these users are placed in the sales funnel.
What reverse ETL can do is to load your product data into Zendesk from your data warehouse and generate an alert that notifies the account managers as soon as a freemium account crosses a defined threshold in your sales funnel.
While Reverse ETL has many benefits, the long-term payoff is in an improved customer experience. By addressing ETL’s woes, reverse ETL puts contextual information at the fingertips of your customer-facing teams. The end result is a seamless, personalized service that enriches the customer experience.
Beat Your Competition With a Personalized Customer Experience
Every organization wants to get the most value out of the data in their data warehouse — because therein lies the answers to serving customers better and creating hyper-personalized experiences. By feeding comprehensive insights to the front-line teams, reverse ETL can help you to improve your customer personalization.
Suppose there’s a winter clothing brand that has the data to identify buyers who bought their winter coats last winter. If they want to launch a winter sale for their previous customers, reverse ETL can help their marketing teams to view detailed information from their tools. This is done by pulling the relevant data directly from the data warehouse and placing it in the software they are already using. They can use this data access to work on a hyper-personalized marketing campaign to appeal to those customers. Hence, by using reverse ETL, you can get a unified view of the customer in all your tools.
In many cases, data has a short shelf life, and needs to be acted on quickly. For example, SaaS companies that follow the Product Led Growth (PLG) model continuously collect product usage data. If a user hits a key milestone in product usage, or gets stuck at a certain point, this information can be shared with the sales or customer support teams for personalized outreach and support at exactly the right moment. Waiting hours or days to act on insights may mean a lost customer or upgrade opportunity.
A real-time data pipeline starts with a streaming ETL platform like Striim that continuously delivers data to your data warehouse. Once there, customer data can be synced to your applications to support your customer-facing team members. Real-time data pipelines underpin superior customer experiences and increased revenue.
To learn more about how Striim supports real-time data integration use cases, please get in touch or try Striim for free today.



