










Insight-driven businesses have the edge over others; they grow at an average of more than 30% annually. Noting this pattern, modern enterprises are trying to become data-driven organizations and get more business value out of their data. But the rise of cloud, the emergence of the Internet of Things (IoT), and other factors mean that data is not limited to on-premises environments.
In addition, there are voluminous amounts of data, many data types, and multiple storage locations. As a consequence, managing data is getting more difficult than ever.
One of the ways organizations are addressing these data management challenges is by implementing a data fabric. Using a data fabric is a viable strategy to help companies overcome the barriers that previously made it hard to access data and process it in a distributed data environment. It empowers organizations to manage mounting amounts of data with more efficiency. Data fabric is one of the more recent additions to the lexicon of data analytics. Gartner listed data fabric as one of the top 10 data and analytics trends for 2021.
- What is a data fabric?
- Why do you need a data fabric in today’s digital world?
- Data fabric examples to consider for improving your organization’s processes
- Security is key to a successful data fabric implementation
- Building your data fabric with Striim
- Learn more: on-demand webinar with James Serra
What is a data fabric?
A data fabric is an architecture that runs technologies and services to help an organization manage its data. This data can be stored in relational databases, tagged files, flat files, graph databases, and document stores.
A data fabric architecture facilitates data-centric tools and applications to access data while working with various services. These can include Apache Kafka (for real-time streaming), ODBC (open database connectivity), HDFS (Hadoop distributed file system), REST (representational state transfer) APIs, POSIX (portable operating system interface), NFS (network file system), and others. It’s also crucial for a data fabric architecture to support emerging standards.
A data fabric is agnostic to architectural approach, geographical locations, data use case, data process, and deployment platforms. With data fabric, organizations can work toward meeting one of their most desired goals: having access to the right data in real-time, with end-to-end governance-and all at a low cost.
Data fabric vs. data lake
Often it happens that organizations lack clarity on what makes a data lake different from a data fabric. A data lake is a central location that stores large amounts of data in its raw and native format.
However, there’s an increase in the trend of data decentralization. Some data engineers believe that it’s not practical to build a central data repository, which you can govern, clean, and update effectively.
On the other hand, a data fabric supports heterogeneous data locations. It simplifies managing data stored in disparate data repositories, which can be a data lake or a data warehouse. Therefore, a data fabric doesn’t replace a data lake. Instead, it helps it to operate better.
Why do you need data fabric in today’s digital world?
Data fabrics empower businesses to use their existing data architectures more efficiently without structurally rebuilding every application or data store. But why is a data fabric relevant today?
Organizations are handling challenges of bigger scalability and complexity. Today, their IT systems are advanced and work with disparate environments while managing existing applications and modern applications powered by microservices.
Previously, software development teams went with their own implementation for data storage and retrieval. A typical enterprise data center stores data in relational databases (e.g., Microsoft SQL Server), non-relational databases (e.g., MongoDB), data repositories (e.g., a data warehouse), flat files, and other platforms. As a result, data is spread across rigid and isolated data silos, which creates issues for modern businesses.
Unifying this data isn’t trivial. Apps store data in a wide range of formats, even if they are using the same data. Besides, organizations store data in various siloed applications. Consolidating this data includes going through data deduplication — a process that removes duplicate copies of repeating data. Taking data to the right application at the right time is desirable, but it’s a tough nut to crack. That’s where a data fabric architecture can resolve your problem.
A data fabric helps to:
- Handle multiple environments simultaneously, including on-premises, cloud, and hybrid.
- Use pre-packaged modules to establish connections to any data source.
- Bolster data preparation, data quality, and data governance capabilities.
- Improve data integration between applications and sources.
A data fabric architecture allows you to map data from different apps, making business analysis easier. Your team can draw decisions and insights from existing and new data points with connected data. For instance, suppose an authorized user in the sales department wants to look at data from marketing. A data fabric lets them access marketing data seamlessly, in the same way they access sales data.
With a data fabric, you can build a global and agile data environment that can track and govern data across applications, environments, and users. For instance, if objects move from one environment to another, the data fabric notifies each component about this change and oversees the required processes, such as what process to run, how to run, and what’s the object’s state.
Data fabric examples to consider for improving your organization’s processes
The flexibility of a data fabric architecture helps in more ways than one. Some of the data fabric examples include the following:
Enhancing machine learning (ML) models
When the right data is fed to machine learning (ML) models in a timely manner, their learning capabilities improve. ML algorithms can be used to monitor data pipelines and recommend suitable relationships and integrations. These algorithms can obtain information from data while being connected to the data fabric, go through all the business data, examine that data, and identify appropriate connections and relationships.
One of the most time-consuming elements of training ML models is getting the data ready. A data fabric architecture helps to use ML models more efficiently by reducing data preparation time. It also aids in increasing the usability of the prepared data across applications and models. When an organization distributes data across on-premises, cloud, and IoT, it’s the data fabric that provides controlled access to secure data, enhancing ML processes.
Building a holistic customer view
Businesses can employ a data fabric to harness data from customer activities and understand how interacting with customers can offer more value. This could include consolidating real-time data of different sales activities, the time it takes to onboard a customer, and customer satisfaction KPIs.
For instance, an IT consulting firm can consolidate data from customer support requests and rework their sales activities accordingly. The firm receives concerns from its clients regarding the lack of a tool that can help them to migrate their on-premises databases to multi-cloud environments without downtime. The firm can then recognize the need to resolve this issue, find a reliable tool like Striim to address it, and have its sales representatives recommend the tool to customers.
Security is key to a successful data fabric implementation
Over the past few years, cyberattacks, especially ransomware attacks, have grown at a rapid rate. So, it’s no surprise organizations are concerned about the risk these attacks pose to their data security while data is being moved from one point to another in the data fabric.
Organizations can improve data protection by incorporating security protocols to protect their data from cyber threats. These protocols include firewalls, IPSec (IP Security), and SFTP (Secure File Transfer Protocol). Another thing to consider is a dynamic and fluid access control policy, which can be adapted dynamically to tackle evolving cyber threats.
With so many cyberattacks causing damages worth millions, securing your data across all points is integral for successfully implementing your data fabric architecture.
This can be addressed in multiple ways:
- Ensuring data at-rest and in-flight are encrypted
- Protecting your networking traffic from the public internet by using PrivateLink on services like Azure and AWS
- Managing secrets and keys securely across clouds
Building your data fabric with Striim
Now that you know the benefits and some use cases of a data fabric, how can you start the transition towards a data fabric architecture in your organization?
According to Gartner, a data fabric should have the following components:
- A data integration backbone that is compatible with a range of data delivery methods (including ETL, streaming, and replication)
- The ability to collect and curate all forms of metadata (the “data about the data”)
- The ability to analyze and make predictions from data and metadata using ML/AI models
- A knowledge graph representing relationships between data
While there are various ways to build a data fabric, the ideal solution simplifies the transition by complementing your existing technology stack. Striim serves as the foundation for a data fabric by connecting with legacy and modern solutions alike. Its flexible and scalable data integration backbone supports real-time data delivery via intelligent pipelines that span hybrid cloud and multi-cloud environments.
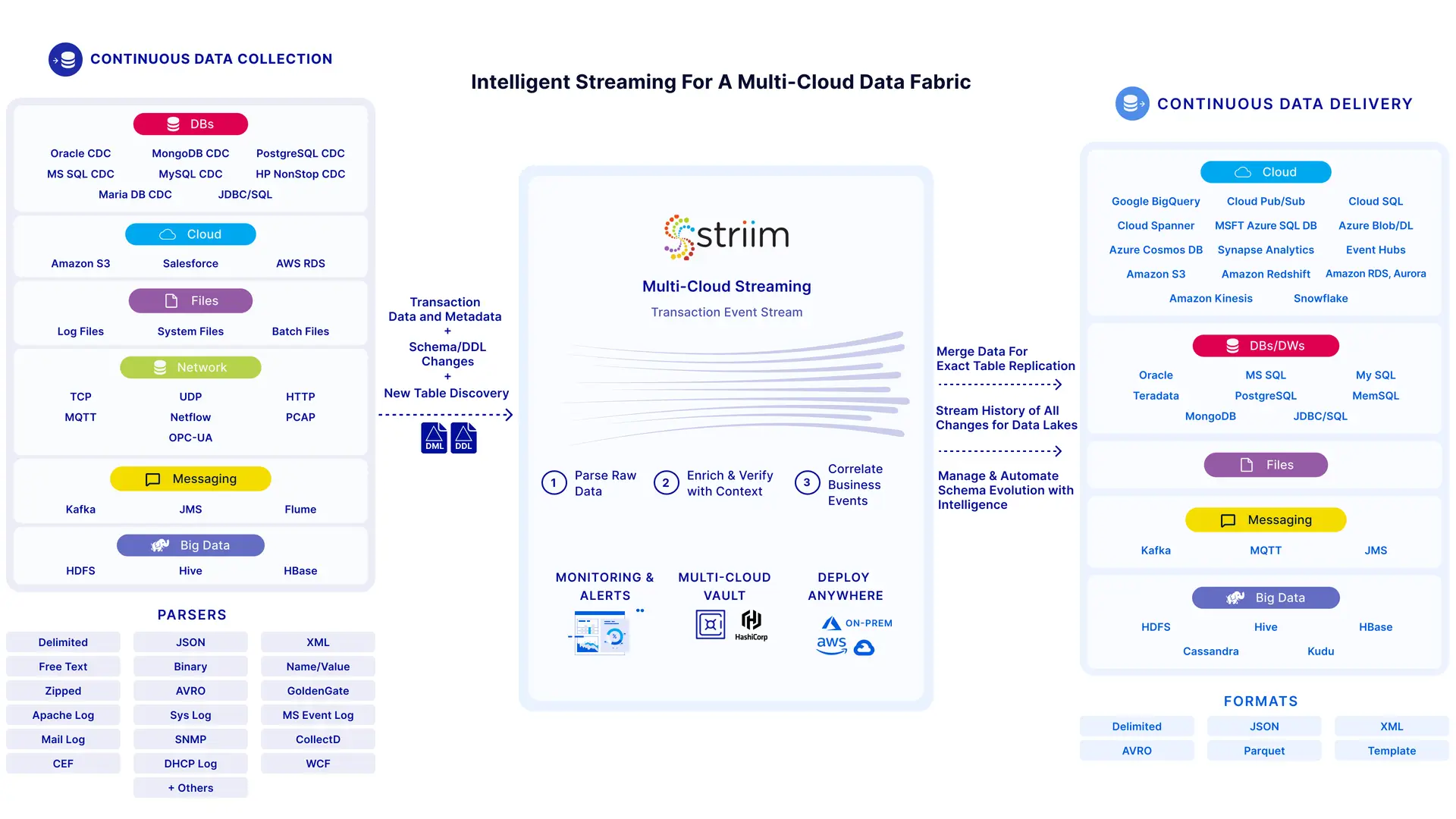
Striim continuously ingests transaction data and metadata from on-premise and cloud sources and is designed ground-up for real-time streaming with:
- An in-memory streaming SQL engine that transforms, enriches, and correlates transaction event streams
- Machine learning analysis of event streams to uncover patterns, identify anomalies, and enable predictions
- Real-time dashboards that bring streaming data to life, from live transaction metrics to business-specific metrics (e.g. suspected fraud incidents for a financial institution or live traffic patterns for an airport)
- Hybrid and multi-cloud vault to store passwords, secrets, and keys. Striim’s vault also integrates seamlessly with 3rd party vaults such as HashiCorp
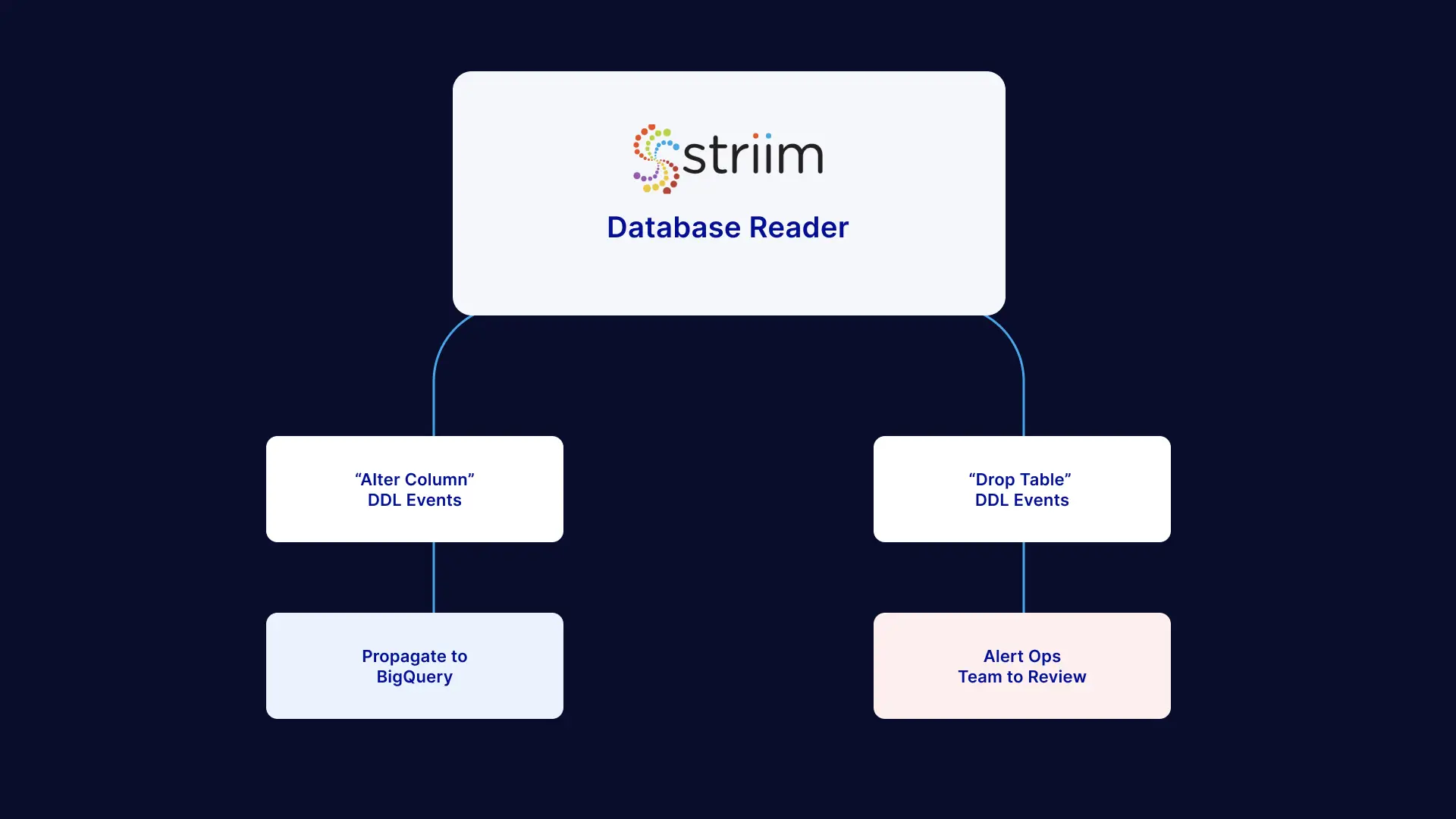
Continuous movement of data (without data loss or duplication) is essential to mission-critical business processes. Whether a database schema changes, a node fails, or a transaction is larger than expected — Striim’s self-healing pipelines resolve the issue via automated corrective actions. For example, Striim detects schema changes in source databases (e.g. create table, drop table, alter column/add column events), and users can set up intelligent workflows to perform desired actions in response to DDL changes.
As shown below, in the case of an “Alter Table” DDL event, Striim is configured to automatically propagate the change to downstream databases, data warehouses and data lakehouses. In contrast, in the case of a “Drop Table” event, Striim is set up to alert the Ops Team.
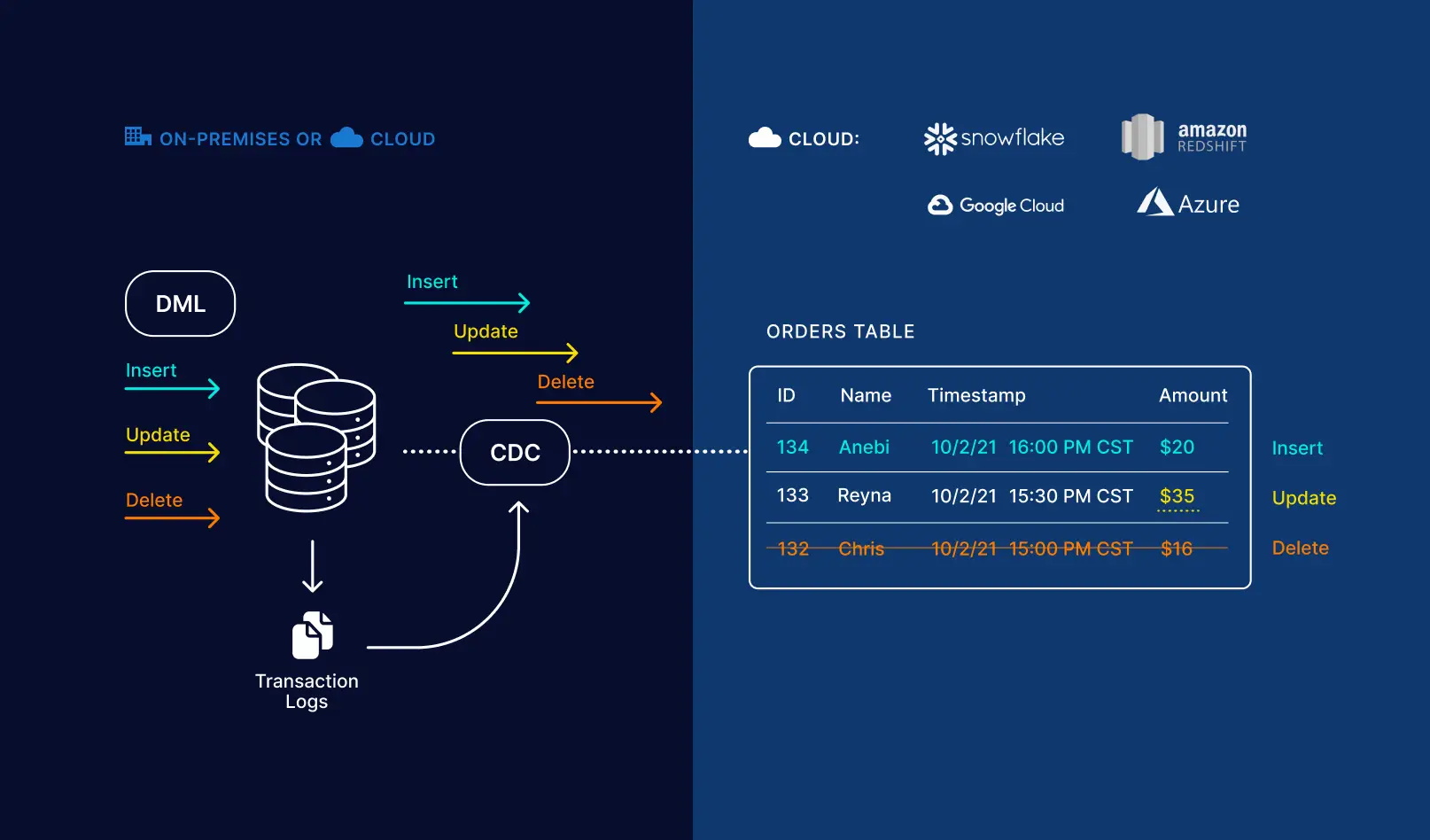
With Striim at its core, a data fabric functions as a comprehensive source of truth — whether you choose to maintain a current snapshot or a historical ledger of your customers and operations. The example below shows how Striim can replicate exact DML statements to the target system, creating an exact replica of the source:
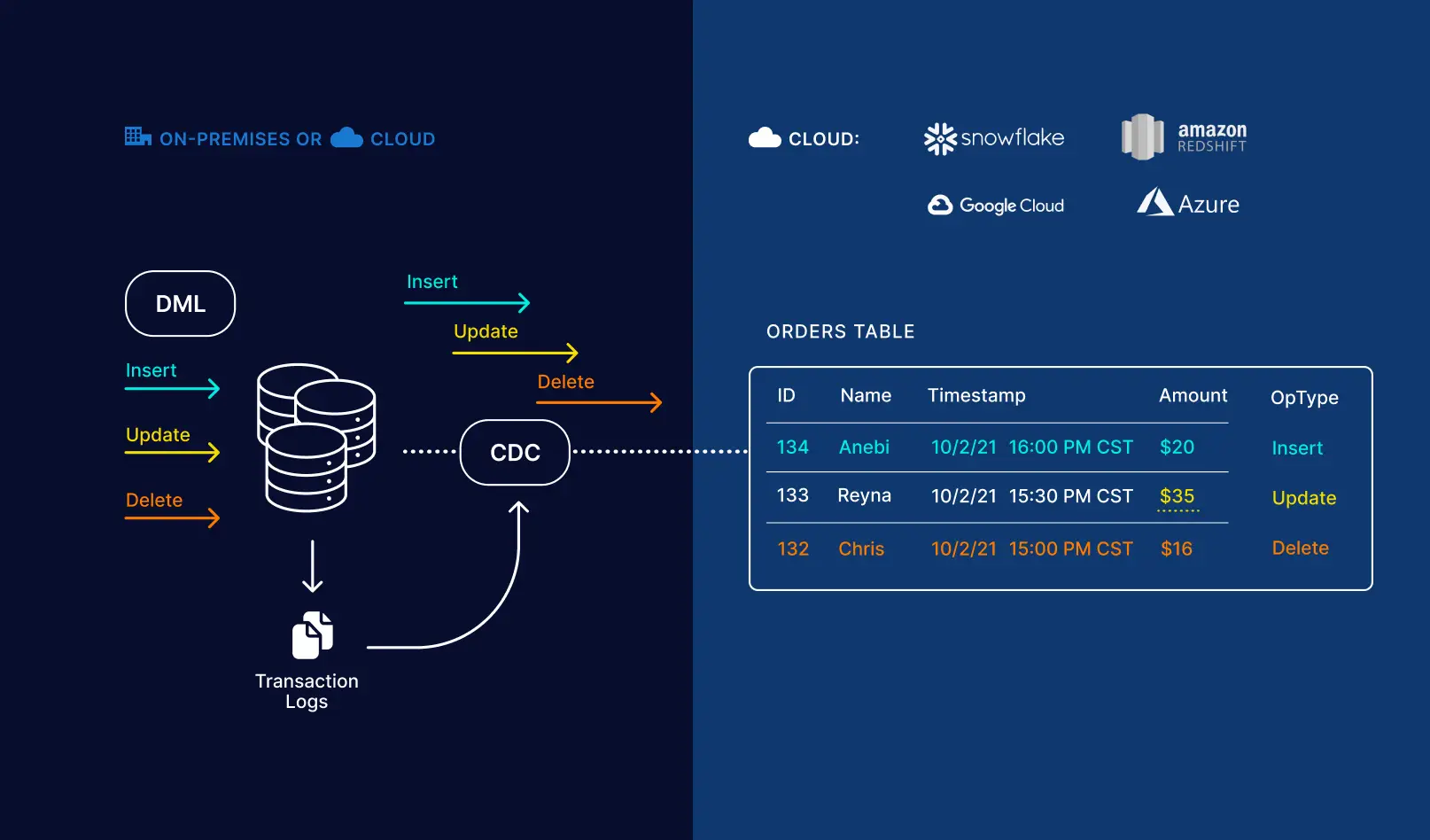
And the following example shows how Striim can be used to maintain a historical record of all the changes in the source system:
Taken together, Striim makes it possible to build an intelligent and secure real-time data fabric across multi-cloud and hybrid cloud environments. Once data is unified in a central destination (e.g. a data warehouse), a data catalog solution can be used to organize and manage data assets.
Learn More: On-Demand Data Fabric Webinar
Looking for more examples and use cases of enterprise data patterns including data fabric, data mesh, and more? Watch our on-demand webinar with James Serra (Data Platform Architecture Lead at EY) on “Building a Multi-Cloud Data Fabric for Analytics”. Topics covered include:
- Pros and cons of multi-cloud vs doubling down on a single cloud
- Enterprise data patterns such as Data Fabric, Data Mesh, and The Modern Data Stack
- Data ingestion and data transformation in a multi-cloud/hybrid cloud environment
- Comparison of data warehouses (Snowflake, Synapse, Redshift, BigQuery) for real-time workloads



