










Data Mesh is revolutionizing event streaming architecture by enabling organizations to quickly and easily integrate real-time data, streaming analytics, and more. With the help of Striim’s enterprise-grade platform, companies can now deploy and manage a data mesh architecture with automated data mapping, cloud-native capabilities, and real-time analytics. In this article, we will explore the advantages and limitations of data mesh, while also providing best practices for building and optimizing a data mesh with Striim. By exploring the benefits of using Data Mesh for your event streaming architecture, this article will help you decide if it’s the right solution for your organization.
What is a Data Mesh and how does it work?
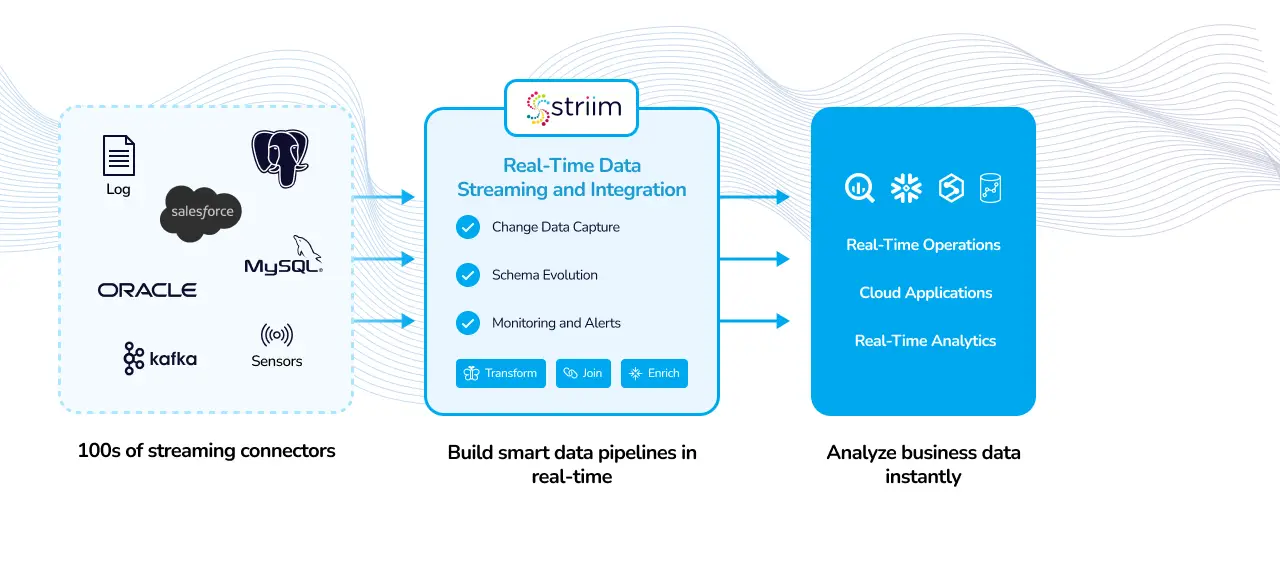
Data Mesh is a revolutionary event streaming architecture that helps organizations quickly and easily integrate real-time data, stream analytics, and more. It enables data to be accessed, transferred, and used in various ways such as creating dashboards or running analytics. The Data Mesh architecture is based on four core principles: scalability, resilience, elasticity, and autonomy.
Data mesh technology also employs event-driven architectures and APIs to facilitate the exchange of data between different systems. This allows for two-way integration so that information can flow from one system to another in real-time. Striim is a cloud-native Data Mesh platform that offers features such as automated data mapping, real-time data integration, streaming analytics, and more. With Striim’s enterprise-grade platform, companies can deploy and manage their data mesh with ease.
Moreover, common mechanisms for implementing the input port for consuming data from collaborating operational systems include asynchronous event-driven data sharing in the case of modern systems like Striim’s Data Mesh platform as well as change data capture (Dehghani, 220). With these mechanisms in place organizations can guarantee a secure yet quick exchange of important information across their networks which helps them maintain quality standards within their organization while also providing insights into customer behaviors for better decision making.
What are the four principles of a Data Mesh, and what problems do they solve?
A data mesh is technology-agnostic and underpins four main principles described in-depth in this blog post by Zhamak Dehghani. The four data mesh principles aim to solve major difficulties that have plagued data and analytics applications for a long time. As a result, learning about them and the problems they were created to tackle is important.
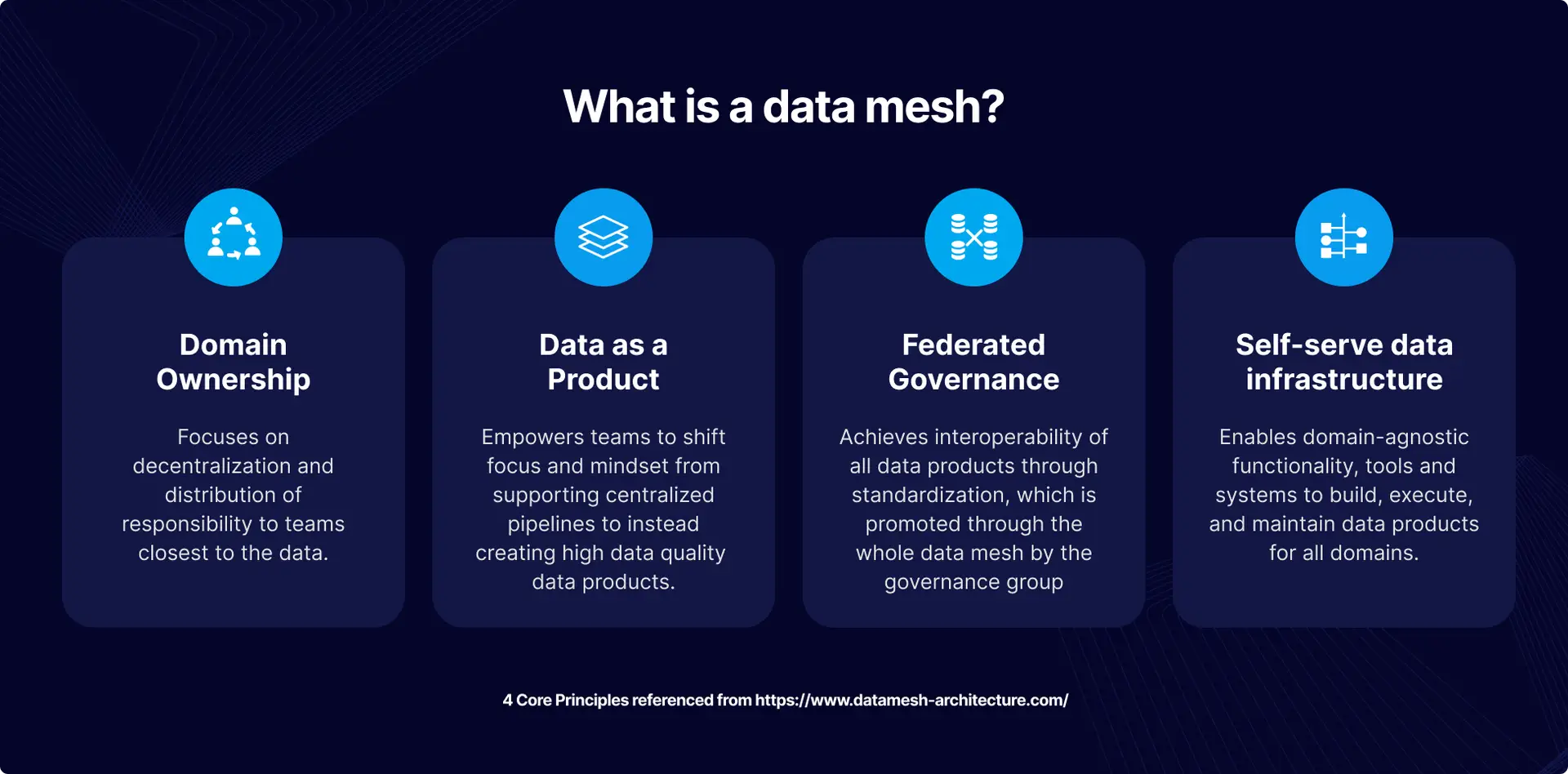
Domain-oriented decentralized data ownership and architecture
This principle means that each organizational data domain (i.e., customer, inventory, transaction domain) takes full control of its data end-to-end. Indeed, one of the structural weaknesses of centralized data stores is that the people who manage the data are functionally separate from those who use it. As a result, the notion of storing all data together within a centralized platform creates bottlenecks where everyone is mainly dependent on a centralized “data team” to manage, leading to a lack of data ownership. Additionally, moving data from multiple data domains to a central data store to power analytics workloads can be time consuming. Moreover, scaling a centralized data store can be complex and expensive as data volumes increase.
There is no centralized team managing one central data store in a data mesh architecture. Instead, a data mesh entrusts data ownership to the people (and domains) who create it. Organizations can have data product managers who control the data in their domain. They’re responsible for ensuring data quality and making data available to those in the business who might need it. Data consistency is ensured through uniform definitions and governance requirements across the organization, and a comprehensive communication layer allows other teams to discover the data they need. Additionally, the decentralized data storage model reduces the time to value for data consumers by eliminating the need to transport data to a central store to power analytics. Finally, decentralized systems provide more flexibility, are easier to work on in parallel, and scale horizontally, especially when dealing with large datasets spanning multiple clouds.
Data as a product
This principle can be summarized as applying product thinking to data. Product thinking advocates that organizations must treat data with the same care and attention as customers. However, because most organizations think of data as a by-product, there is little incentive to package and share it with others. For this reason, it is not surprising that 87% of data science projects never make it to production.
Data becomes a first-class citizen in a data mesh architecture with its development and operations teams behind it. Building on the principle of domain-oriented data ownership, data product managers release data in their domains to other teams in the form of a “product.” Product thinking recognizes the existence of both a “problem space” (what people require) and a “solution space” (what can be done to meet those needs). Applying product thinking to data will ensure the team is more conscious of data and its use cases. It entails putting the data’s consumers at the center, recognizing them as customers, understanding their wants, and providing the data with capabilities that seamlessly meet their demands. It also answers questions like “what is the best way to release this data to other teams?” “what do data consumers want to use the data for?” and “what is the best way to structure the data?”
Self-serve data infrastructure as a platform
The principle of creating a self-serve data infrastructure is to provide tools and user-friendly interfaces so that generalist developers (and non-technical people) can quickly get access to data or develop analytical data products speedily and seamlessly. In a recent McKinsey survey, organizations reported spending up to 80% of their data analytics project time on repetitive data pipeline setup, which ultimately slowed down the productivity of their data teams.
The idea of the self-serve data infrastructure as a platform is that there should be an underlying infrastructure for data products that the various business domains can leverage in an organization to get to the work of creating the data products rapidly. For example, data teams should not have to worry about the underlying complexity of servers, operating systems, and networking. Marketing teams should have easy access to the analytical data they need for campaigns. Furthermore, the self-serve data infrastructure should include encryption, data product versioning, data schema, and automation. A self-service data infrastructure is critical to minimizing the time from ideation to a working data-driven application.
Federated computational governance
This principle advocates that data is governed where it is stored. The problem with centralized data platforms is that they do not account for the dynamic nature of data, its products, and its locations. In addition, large datasets can span multiple regions, each having its own data laws, privacy restrictions, and governing institutions. As a result, implementing data governance in this centralized system can be burdensome.
The data mesh more readily acknowledges the dynamic nature of data and allows for domains to designate the governing structures that are most suitable for their data products. Each business domain is responsible for its data governance and security, and the organization can set up general guiding principles to help keep each domain in check.
While it is prescriptive in many ways about how organizations should leverage technology to implement data mesh principles, perhaps the more significant implementation challenge is how that data flows between business domains.
Deploy an API spec in low-code for your Data Mesh with Striim
For businesses looking to leverage the power of Data Mesh, Striim is an ideal platform to consider. It provides a comprehensive suite of features that make it easy to develop and manage applications in multiple cloud environments. The low-code, SQL-driven platform allows developers to quickly deploy data pipelines while a comprehensive API spec enables custom and scalable management of data streaming applications. Additionally, Striim offers resilience and elasticity that can be adjusted depending on specific needs, as well as best practices for scalability and reliability.
The data streaming capabilities provided by Striim are fast and reliable, making it easy for businesses to get up and running quickly. Its cloud agnostic features allow users to take advantage of multiple cloud environments for wider accessibility. With its comprehensive set of connectors, you can easily integrate external systems into your data mesh setup with ease.
While monolithic data operations have accelerated adoption of analytics within organizations, centralized data pipelines can quickly grow into bottlenecks due to lack of domain ownership and focus on results.
To address this problem, using a data mesh and tangential Data Mesh data architectures are rising in popularity. A data mesh is an approach to designing modern distributed data architectures that embrace a decentralized data management approach.
Benefits of Using Data Mesh Domain Oriented Decentralization approach for data enables faster and efficient real-time cross domain analysis. A data mesh is an approach that is primitively based on four fundamental principles that makes this approach a unique way to extract the value of real-time data productively. The first principle is domain ownership, that allows domain teams to take ownership of their data. This helps in domain driven decision making by experts. The second principle promotes data as a product. This also helps teams outside the domain to use the data when required and with the product philosophy, the quality of data is ensured. The third principle is a self-serve data infrastructure platform. A dedicated team provides tools to maintain interoperable data products for seamless consumption of data by all domains that eases creation of data products. The final principle is federated governance that is responsible for setting global policies on the standardization of data. Representatives of every domain agree on the policies such as interoperability (eg: source file format), role based access for security, privacy and compliance
In short, Striim is an excellent choice for companies looking to implement a data mesh solution due to its fast data streaming capabilities, low-code development platform, comprehensive APIs, resilient infrastructure options, cloud agnostic features, and features that support creating a distributed data architecture. By leveraging these features – businesses can ensure that their data mesh runs smoothly – allowing them to take advantage of real-time analytics capabilities or event-driven architectures for their operations!
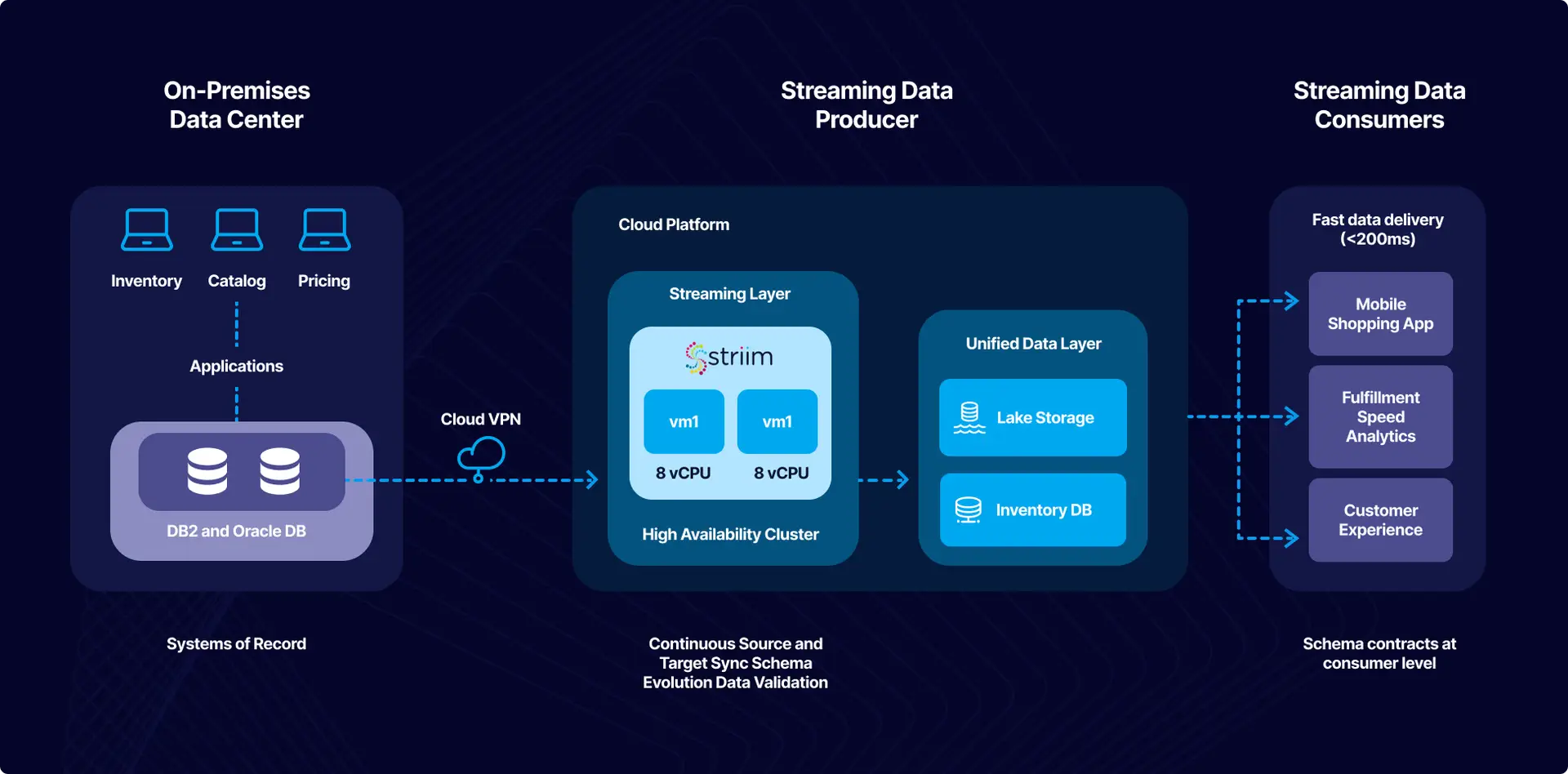
Benefits of using Striim for Data Mesh Architecture
Using Striim for Data Mesh architecture provides a range of benefits to businesses. As an enterprise-grade platform, Striim enables the quick deployment and management of data meshes, to automated data mapping and real-time analytics capabilities. Striim offers an ideal solution for businesses looking to build their own Data Mesh solutions.
Striim’s low-code development platform allows businesses to rapidly set up their data mesh without needing extensive technical knowledge or resources. Additionally, they can make use of comprehensive APIs to easily integrate external systems with their data mesh across multiple cloud environments. Automated data mapping capabilities help streamline the integration process by eliminating the need for manual processing or complex transformations when dealing with large datasets from different sources.
Real-time analytics are also facilitated by Striim with its robust event-driven architectures that provide fast streaming between systems as well as secure authentication mechanisms for safeguarding customer data privacy during transmission over networks. These features offer businesses an optimal foundation on which they can confidently construct a successful data mesh solution using Striim’s best practices.
Best practices for building and optimizing a Data Mesh with Striim
Building and optimizing a data mesh with Striim requires careful planning and implementation. It’s important to understand the different use cases for a data mesh and choose the right tool for each one. For example, if data is being exchanged between multiple cloud environments, it would make sense to leverage Striim’s cloud-agnostic capabilities. It’s also important to ensure that all components are properly configured for secure and efficient communication.
Properly monitoring and maintaining a data mesh can help organizations avoid costly downtime or data loss due to performance issues. Striim provides easy-to-use dashboards that provide real-time insights into your event streams, allowing you to quickly identify potential problems. It’s also important to plan for scalability when building a data mesh since growth can often exceed expectations. Striim makes this easier with its automated data mapping capabilities, helping you quickly add new nodes as needed without disrupting existing operations.
Finally, leveraging Striim’s real-time analytics capabilities can help organizations gain greater insight into their event streams. By analyzing incoming events in real time, businesses can quickly identify trends or patterns they might have otherwise missed by simply relying on historical data. This information can then be used to improve customer experiences or develop more efficient business processes. With these best practices in mind, companies can ensure their data mesh is secure, efficient, and optimized for maximum performance.
Conclusion – Is a Data Mesh architecture the right solution for your event stream solution?
When it comes to optimizing your event stream architecture, data mesh is a powerful option worth considering. It offers numerous advantages over traditional architectures, including automated data mapping, cloud-native capabilities, scalability, and elasticity. Before committing resources towards an implementation, organizations should carefully evaluate its suitability based on their data processing needs, dataset sizes, and existing infrastructure.
Organizations that decide to implement a Data Mesh solution should use Striim as their platform of choice to reap the maximum benefits of this revolutionary architecture. With its fast data streaming capabilities, low-code development platform and comprehensive APIs businesses can make sure their Data Mesh runs smoothly and take advantage of real-time analytics capabilities and event-driven architectures.




