Data pipelines can be tricky business —failed jobs, re-syncs, out-of-memory errors, complex jar dependencies, making them not only messy but often disastrously unreliable. Data teams want to innovate and do awesome things for their company, but they get pulled back into firefighting and negotiating technical debt.
The Power of Declarative Streaming Pipelines
Declarative pipelines allow developers to specify what they want to achieve in concise, expressive code. This approach simplifies the creation, management, and maintenance of data pipelines. With Striim, users can leverage SQL-based configurations to define source connectors, target endpoints, and processing logic, making the entire process intuitive and accessible, all while delivering highly consistent, real-time data applied as merges and append-only change-records.
How Striim pipelines work

Striim pipelines streamline the process of data integration and real-time analytics. A pipeline starts with defining a source, which could be a database, log, or other data stream. Striim supports advanced recovery semantics such as A1P (At Least Once Processing) or E1P (Exactly Once Processing) to ensure data reliability.
You can see the full list of connectors stream supports here. →
The data flows into an output stream, which can be configured to reside in-memory for low-latency operations or be Kafka-based for distributed processing. Continuous queries on these materialized streams allow real-time insights and actions. Windowing functions enable efficient data aggregation over specific timeframes. As the data is processed, it is materialized into downstream targets such as databases or data lakes. Striim ensures data accuracy by performing merges with updates and deletes, maintaining a true and consistent view of the data across all targets.
Here we’ll look at an application that reads data from Stripe, replicates data to BigQuery in real-time, then while the data is in flight, detect declined transactions and send slack alerts in real-time.
Striim’s Stripe Analytics Pipeline
Let’s dive into a practical example showcasing the power and simplicity of Striim’s streaming pipelines. The following is a Stripe analytics application that reads data from Stripe, processes it for fraudulent transactions, and generates alerts.
Application Setup
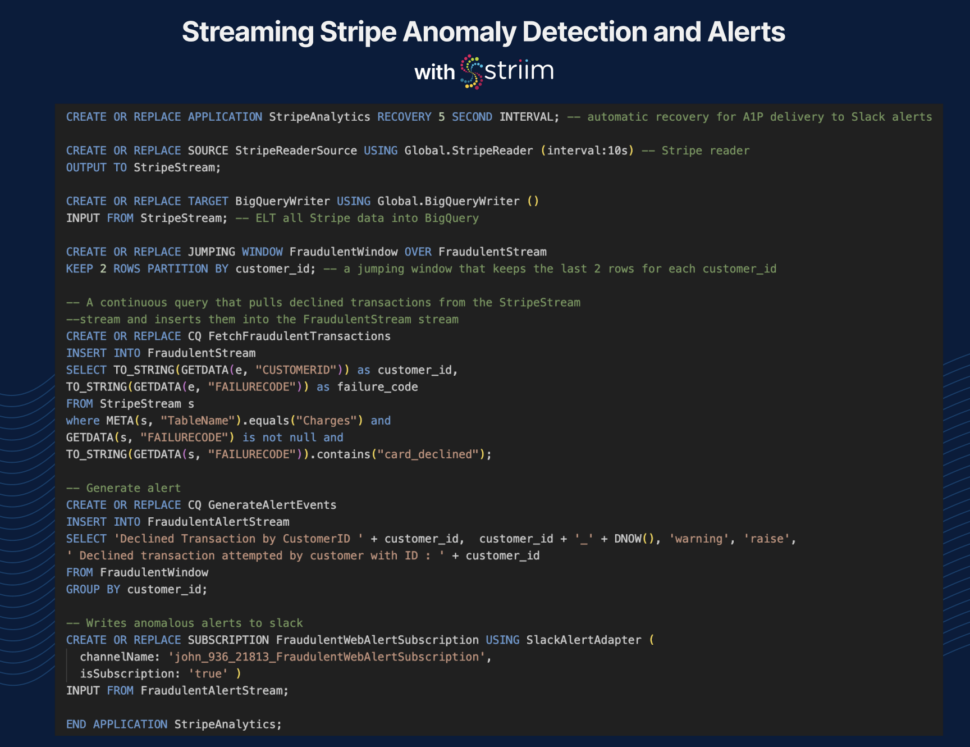
The first step is to create an application that manages the data streaming process. The `StripeAnalytics` application is designed to handle Stripe data, process fraudulent transactions, and generate alerts.
Striim’s declarative approach offers several benefits:
- Simplicity: SQL-based streaming pipelines make it easy to define rich processing logic.
- Scalability: Striim handles large volumes of data efficiently by scaling up and horizontally as a fully managed service, ensuring real-time processing and delivery.
- Flexibility: The ability to integrate with various data sources and targets provides unparalleled flexibility.
- Reliability: Built-in recovery mechanisms ensure data integrity and continuous operation.
- Consistency: Striim delivers consistent data across all targets, maintaining accuracy through precise merges, updates, and deletes.
- Portability: Striim can be deployed in our fully managed service, or run in your own cloud a multi-node cluster containerized with kubernetes.
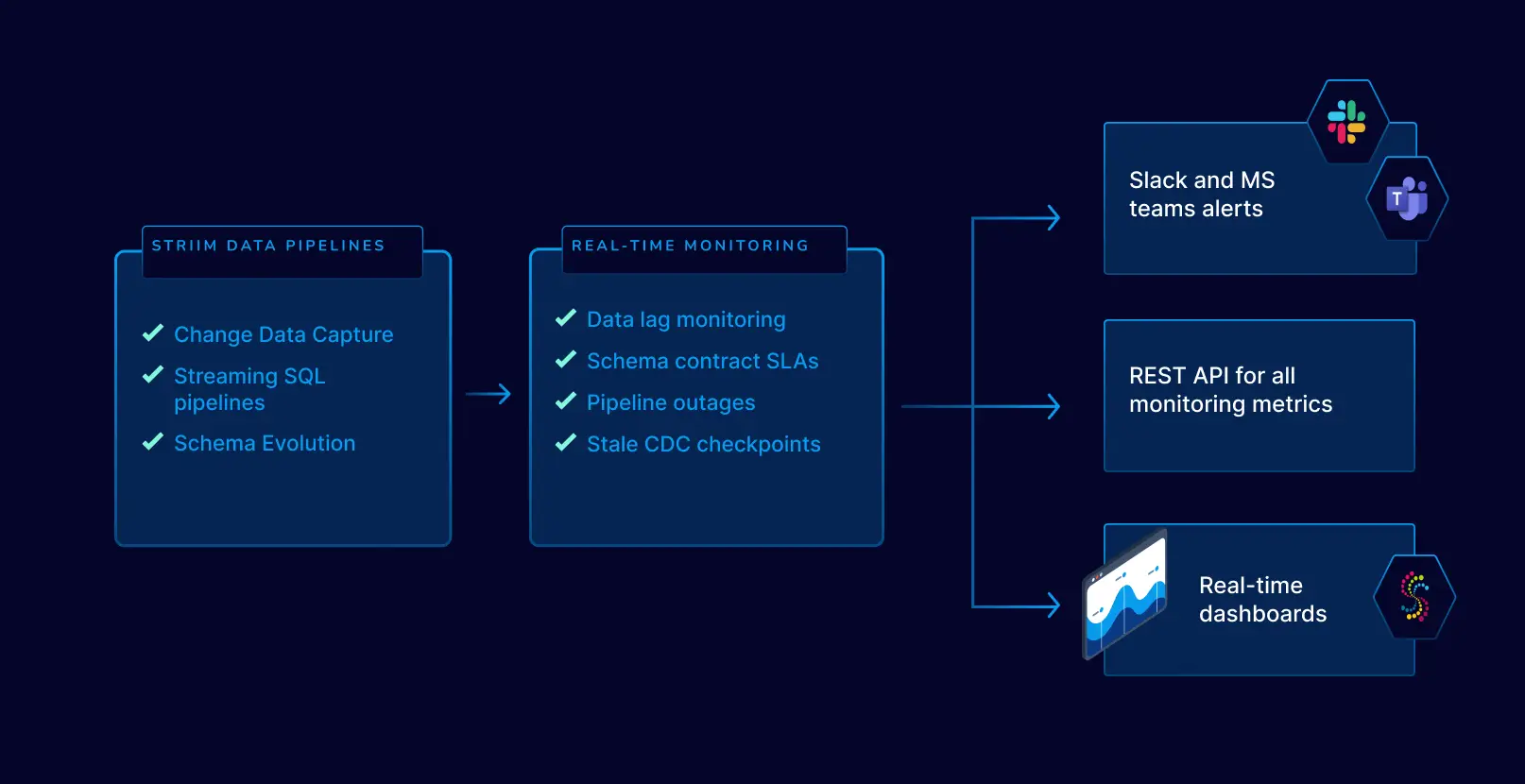
Monitoring and Reliability
Are your reports stale? Is data missing or inconsistent? Striim allows you to drill down into these metrics and gives you out-of-the-box slack alerts so your pipelines are always running on autopilot.