Use Case
Imagine you are staying at a hotel, “Hotel California”, and from the moment you check-in until you check-out, they charge your credit card with a series of “auth/hold” transactions. At check-out the hotel creates a “Charge” transaction against the prior authorizations for the total bill, which is essentially a total sum of all charges incurred by you during your stay.
Your financial institution, “First Wealth Bank”, has a streaming transaction pattern where one or more Credit Card Authorization Hold (A) events are followed by a Credit Card Charge (B) event or a Timeout (T) event which is intended to process your charges accurately.
With Pattern Matching & Partitioning, Striim can match these sequences of credit card transactions in real-time, and output these transactions partitioned by their identifiers (i.e Credit Card/Account/Session ID numbers) which would ultimately simplify the customer experience.
Data Field (with assumptions)
BusinessID = HotelCalifornia
CustomerName = John Doe
CC_Number = Credit-Card/Account number used by customer.
ChargeSessionID (assumption) = CSNID123 – we are assuming this is an id that First Wealth Bank provides as part of authorization transaction response. This id repeats for all subsequent incremental authorizations. If not, we will have to use CreditCard number.
Amount = hold authorization amount in dollars or final payment charge.
TXN_Type = AUTH/HOLD or CHARGE
TXN_Timestamp = datetime when transaction was entered.

As shown in the above schematic, credit card transactions are recorded in financial institutions (in this case, First Wealth Bank) which is streamed in real-time. Data enrichment and processing takes place using Striim’s Continuous Query. Credit card numbers are masked for anonymization, followed by partitioning based on identifiers (credit card numbers). The partitioned data is then queried to check the pattern in downstream processing, ‘Auth/Hold’ followed by ‘Charge’ or ‘Auth/Hold’ followed by ‘Timeout’ for each credit.
Step 1: Configure your source
For this tutorial, you can either use MySQL CDC to replicate a real-life business scenario or a csv file if you do not have access to MySQL database.
Striim Demo w/ MySQL CDC
A CDC pipeline that has MySQL/Oracle as source with above data added as sequence of events. The output are two files, CompletePartitions (Pattern Matched) and TimedOutPartitions (Timer ran down with incomplete CHARGE) for each identifier (Credit Card Number/ Session id).
Demo Data Size
1 million events (transactions) over 250,000 partitions
- 50,000 partitions for success/complete partitions
- 200,000 partitions for incomplete/timed-out partitions
The Python script that writes data to your SQL database can be found here.

Striim Demo w/ FileReader CDC-like Behavior
A File Reader-Writer pipeline that can be run locally without relying on a external working database.
This utilizes a python script to write data into a csv file.

Step 2: Mask the Credit Card Numbers
Striim utilizes inbuilt masking function to anonymize personally identifiable information like credit card numbers. The function maskCreditCardNumber(String value, String functionType) masks the credit card number partially or fully as specified by the user. We use a Continuous Query to read masked data from the source.


Step 4: Split the data into Complete and TimedOut Criteria
In this step, two Continuous Queries are written to split the data into two categories. One where the credit cards has been Charged and other where there was no charge until timeout.

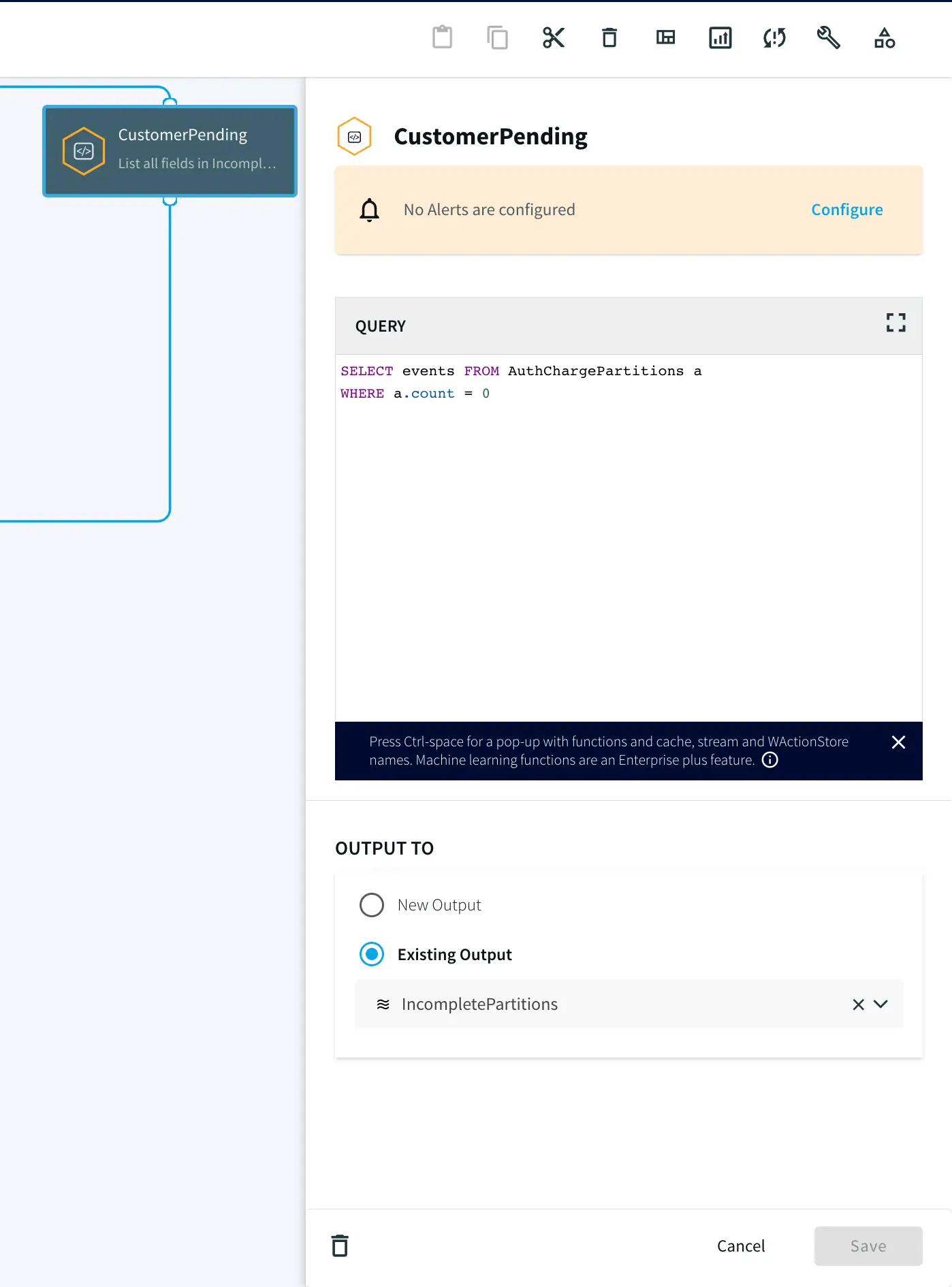
Step 5: Write the Output using FileWriter
Once all events (‘A’ and ‘B’) are accumulated in the partition, two different files are written, one where timers ran down with incomplete charge and other where the credit card was actually charged after auth/hold.
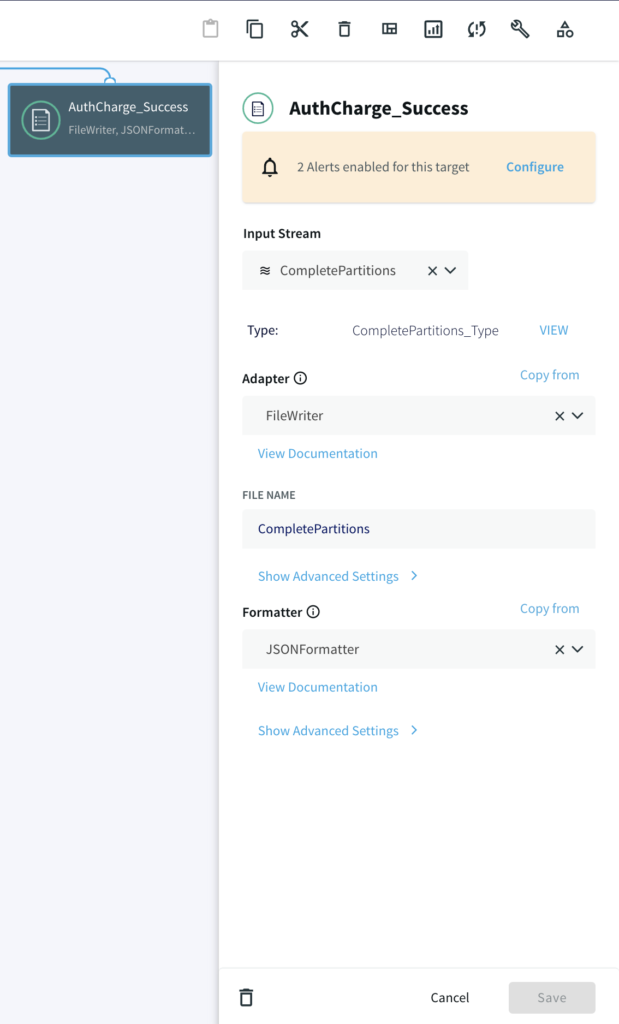
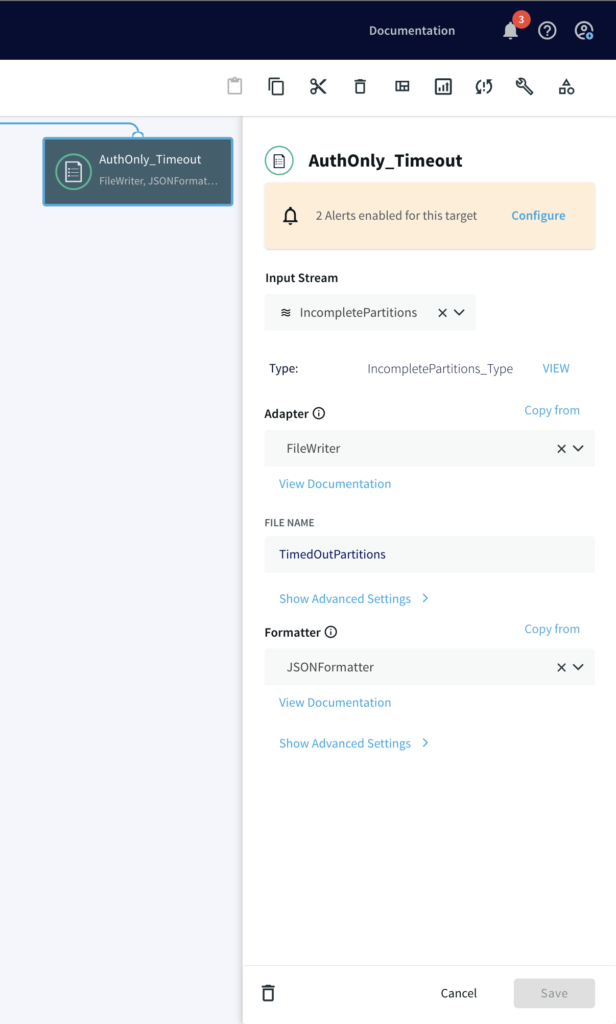
Run the Striim App
You can import the TQL file from here and run the app by selecting ‘Deploy’ followed by ‘Start App’ from the dropdown as shown below:

Once the Striim app starts running you can monitor the input and output data from the UI. To learn more about app monitoring, please refer to the documentation here.

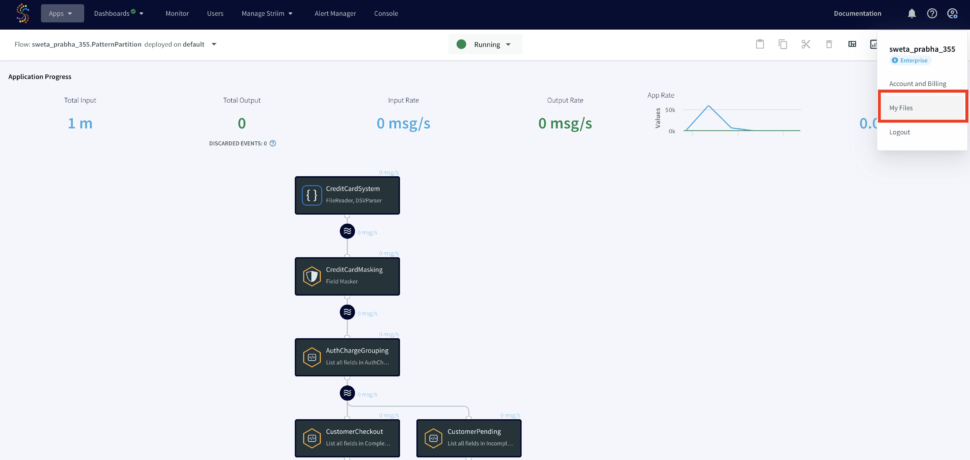
The output files will be stores under ‘My Files’ in the web UI as shown below:

Striim
Striim’s unified data integration and streaming platform connects clouds, data and applications.
Oracle Database
Oracle is a multi-model relational database management system.
Apache Kafka
Apache Kafka is an open-source distributed streaming system used for stream processing, real-time data pipelines, and data integration at scale.
Azure Cosmos
Azure Cosmos is a fully managed NoSQL database.
Azure Blob Storage
Azure Blob Storage is an object store designed to store massive amounts of unstructured data.