










When implemented effectively, smart data pipelines seamlessly integrate data from diverse sources, enabling swift analysis and actionable insights. They empower data analysts and business users alike by providing critical information while protecting sensitive production systems. Unlike traditional pipelines, which can be hampered by various challenges, smart data pipelines are designed to address these issues head-on.
Today, we’ll dive into what makes smart data pipelines distinct from their traditional counterparts. We’ll explore their unique advantages, discuss the common challenges you face with traditional data pipelines, and highlight nine key capabilities that set smart data pipelines apart.
What is a Smart Data Pipeline?
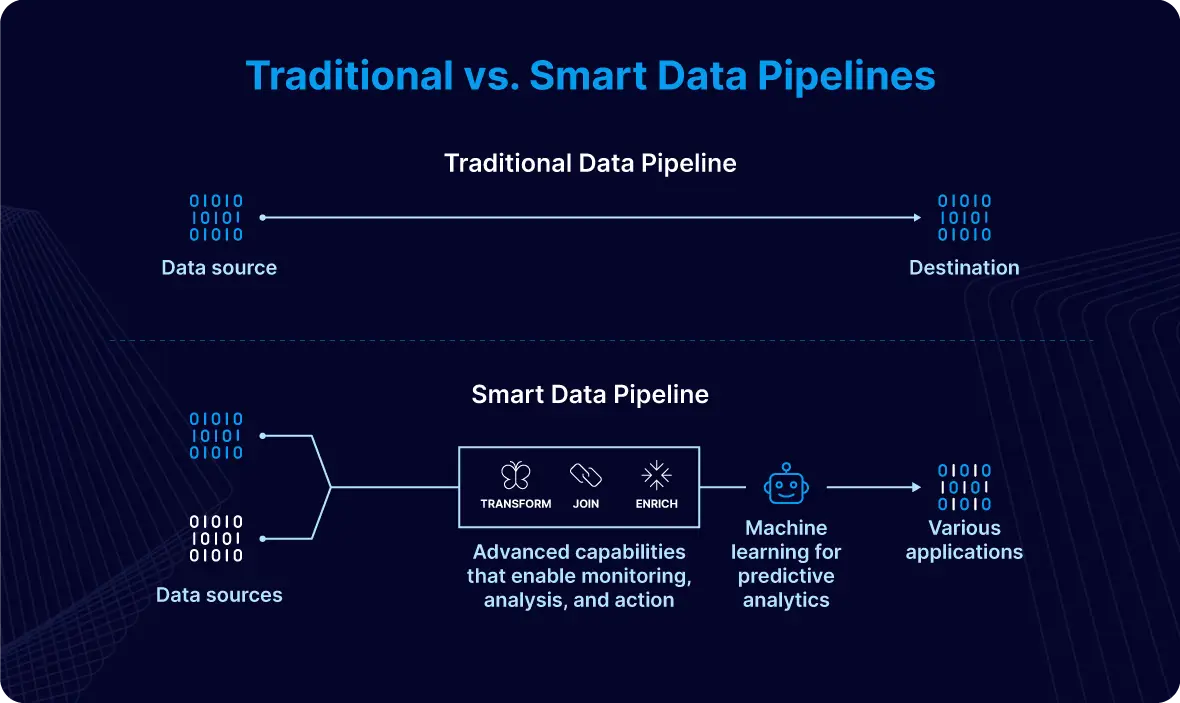
A smart data pipeline is a sophisticated, intelligent data processing system designed to address the dynamic challenges and opportunities of today’s fast-paced world. In contrast to traditional data pipelines, which are primarily designed to move data from one point to another, a smart data pipeline integrates advanced capabilities that enable it to monitor, analyze, and act on data as it flows through the system.
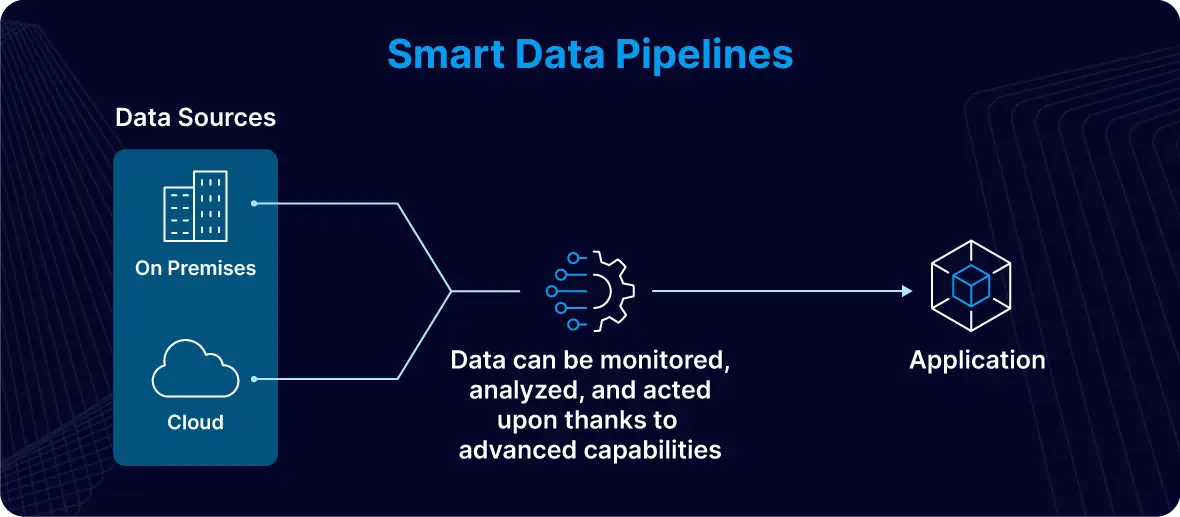
This real-time responsiveness allows organizations to stay ahead of the competition by seizing opportunities and addressing potential issues with agility. For instance, your smart data pipeline can rapidly identify and capitalize on an emerging social media trend, allowing your business to adapt its marketing strategies and engage with audiences effectively before the trend peaks. This gets you ahead of your competition. Alternatively, it can also help mitigate the impact of critical issues, such as an unexpected schema change in a database, by automatically adjusting data workflows or alerting your IT team to resolve the problem right away.
In addition to real-time monitoring and adaptation, smart data pipelines leverage features such as machine learning for predictive analytics. This enables businesses to anticipate future trends or potential problems based on historical data patterns, facilitating proactive decision-making. Moreover, a decentralized architecture enhances data accessibility and resilience, ensuring that data remains available and actionable even in the face of system disruptions or increased demand.
To fully comprehend why traditional data pipelines are insufficient, let’s walk through some of their hurdles.
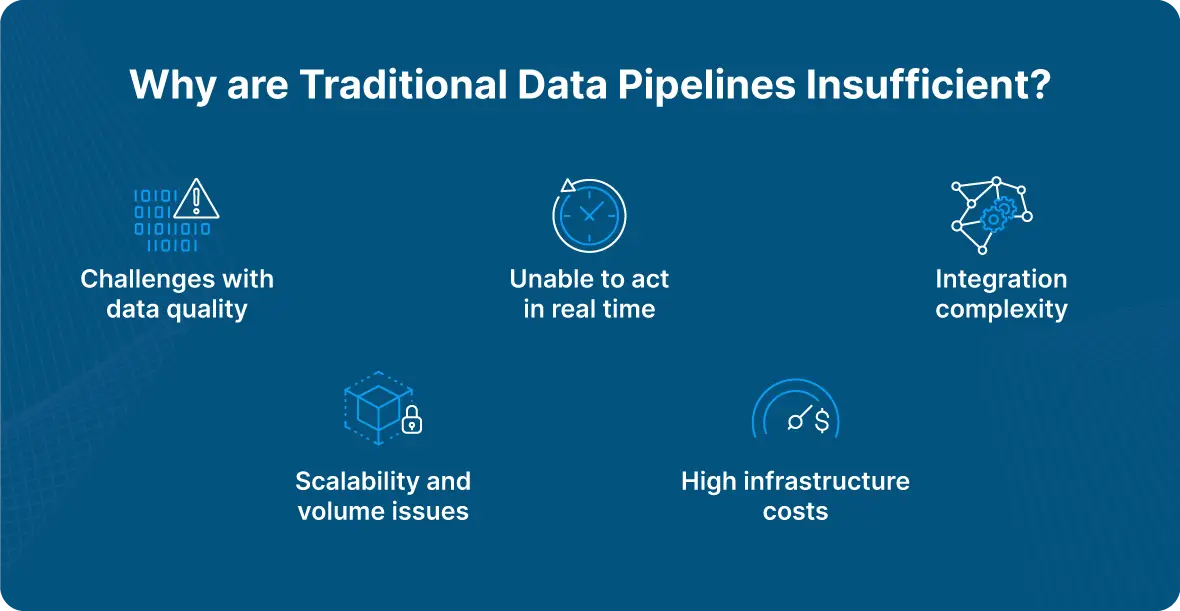
What are the Challenges of Building Data Pipelines?
Traditional data pipelines face several persistent issues that reveal the need for smarter solutions. Luckily, smart data pipelines can mitigate these problems.
According to Dmitriy Rudakov, Director of Solution Architecture at Striim, there are two primary features that smart data pipelines have that traditional ones don’t. “[The] two main aspects [are] the ability to act in real time, and integration with SQL / UDF layer that allows any type of transformations,” he shares.
Furthermore, with traditional data pipelines, data quality remains a significant challenge, as manual cleansing and integration of separate sources can cause trouble. As a result, errors and inconsistencies can be introduced into your data. Integration complexity adds to the difficulty, with custom coding required to connect various data sources, leading to extended development times and maintenance hassles. Then, there’s the question of scalability and data volume. This is problematic for traditional pipelines as they often struggle with the increasing scale and velocity of data, resulting in performance bottlenecks. Plus, high infrastructure costs are another hurdle.
With traditional data pipelines, the data processing and transformation stages can be rigid and labor-intensive, too. This makes it near impossible to adapt to new data requirements rapidly. Finally, traditional pipelines raise questions about pipeline reliability and security, as they are prone to failures and security vulnerabilities.
By moving to a smart data pipeline, you can rest assured that your data is efficiently managed, consistently available, and adaptable to evolving business needs. Let’s dive deeper into key aspects of smart data pipelines that allow them to address all of these concerns.
9 Key Features of Smart Data Pipelines
Here are nine key capabilities of Smart Data Pipelines that your forward-thinking enterprise cannot afford to overlook.
Real-time Data Integration
Smart data pipelines are adept at handling real-time data integration, which is crucial for maintaining up-to-date insights in today’s dynamic business environment. These pipelines feature advanced connectors that interface seamlessly with a variety of data sources, such as databases, data warehouses, IoT devices, messaging systems, and applications. The best part? This all happens in real time.
Rudakov believes this is the most crucial aspect of smart data pipelines. “I would zoom into [the] first [capability as the most important] — real time, as it gives one an ability to act as soon as an event is seen and not miss the critical time to help save money for the business. For example, in the IoT project we did for a car breaks manufacturer, if the quality alert went out too late the company would lose critical time to fix the device.”
By supporting real-time data flow, smart pipelines ensure that data is continuously updated and synchronized across multiple systems. This enables businesses to access and utilize current information instantly, which facilitates faster decision-making and enhances overall operational efficiency. While traditional data pipelines face delays and limited connectivity, smart data pipelines are agile, and therefore able to keep pace with the demands of real-time data processing.
Location-agnostic
Another feature of the smart data pipeline is that it offers flexible deployment, making it truly location-agnostic. Your team can launch and operate smart data pipelines across various environments, whether the data resides on-premises or in the cloud.
This capability allows organizations to seamlessly integrate and manage data across various locations without being constrained by the physical or infrastructural limitations of traditional pipelines.
Additionally, smart data pipelines are able to operate fluidly across both on-premises and cloud environments. This cross-environment functionality gives businesses an opportunity to develop a hybrid data architecture tailored to their specific requirements.
Whether your organization is transitioning to the cloud, maintaining a multi-cloud strategy, or managing a complex mix of on-premises and cloud resources, smart data pipelines adapt to all of the above situations — and seamlessly. This adaptability ensures that data integration and processing remain consistent and efficient, regardless of where the data is stored or how your infrastructure evolves.
Applications on streaming data
Another reason smart data pipelines emerge as better than traditional is thanks to their myriad of uses. The utilization of smart data pipelines extend beyond simply delivering data from one place to another. Instead, smart data pipelines enable users to easily build applications on streaming data, ideally with a SQL-based engine that’s familiar to developers and data analysts alike. It should allow for filtering, transforming, and data enrichment, for use cases such as PII masking, data denormalization, and more.
Smart data pipelines also incorporate machine learning on streaming data to make predictions and detect anomalies (Think: fraud detection by financial institutions). They also enable automated responses to critical operational events via alerts, live monitoring dashboards, and triggered actions.
Scalability
Scalability is another key capability. The reason smart data pipelines excel in scalability is because they leverage a distributed architecture that allocates compute resources across independent clusters. This setup allows them to handle multiple workloads in parallel efficiently, unlike traditional pipelines which often struggle under similar conditions.
Organizations can easily scale their data processing needs by adding more smart data pipelines, easily integrating additional capacity without disrupting existing operations. This elastic scalability ensures that data infrastructure can grow with business demands, maintaining performance and flexibility.
Reliability
Next up is reliability. If your organization has ever experienced the frustration of a traditional data pipeline crashing during peak processing times—leading to data loss and operational downtime—then you understand why reliability is of paramount importance.
For critical data flows, smart data pipelines offer robust reliability by ensuring exactly-once or at-least-once processing guarantees. This means that each piece of data is processed either once and only once, or at least once, to prevent data loss or duplication. They are also designed with failover capabilities, allowing applications to seamlessly switch to backup nodes in the event of a failure. This failover mechanism ensures zero downtime, maintaining uninterrupted data processing and system availability even in the face of unexpected issues.
Schema evolution for database sources
Furthermore, these pipelines can handle schema changes in source tables—such as the addition of new columns—without disrupting data processing. Equipped with schema evolution capabilities, these pipelines allow users to manage Data Definition Language (DDL) changes flexibly.
Users can configure how to respond to schema updates, whether by halting the application until changes are addressed, ignoring the modifications, or receiving alerts for manual intervention. This is invaluable for pipeline operability and resilience.
Pipeline monitoring
The integrated dashboards and monitoring tools native to smart data pipelines offer real-time visibility into the state of data flows. These built-in features help users quickly identify and address bottlenecks, ensuring smooth and efficient data processing.
Additionally, smart data pipelines validate data delivery and provide comprehensive visibility into end-to-end lag, which is crucial for maintaining data freshness. This capability supports mission-critical systems by adhering to strict service-level agreements (SLAs) and ensuring that data remains current and actionable.
Decentralized and decoupled
In response to the limitations of traditional, monolithic data infrastructures, many organizations are embracing a data mesh architecture to democratize access to data. Smart data pipelines play a crucial role in this transition by supporting decentralized and decoupled architectures.
This approach allows an unlimited number of business units to access and utilize analytical data products tailored to their specific needs, without being constrained by a central data repository. By leveraging persisted event streams, Smart Data Pipelines enable data consumers to operate independently of one another, fostering greater agility and reducing dependencies. This decentralized model not only enhances data accessibility but also improves resilience, ensuring that each business group can derive value from data in a way that aligns with its unique requirements.
Able to do transformations and call functions
A key advantage of smart data pipelines is their ability to perform transformations and call functions seamlessly. Unlike traditional data pipelines that require separate processes for data transformation, smart data pipelines integrate this capability directly.
This allows for real-time data enrichment, cleansing, and modification as the data flows through the system. For instance, a smart data pipeline can automatically aggregate sales data, filter out anomalies, or convert data formats to ensure consistency across various sources.
Build Your First Smart Data Pipeline Today
Data pipelines form the basis of digital systems. By transporting, transforming, and storing data, they allow organizations to make use of vital insights. However, data pipelines need to be kept up to date to tackle the increasing complexity and size of datasets. Smart data pipelines streamline and accelerate the modernization process by connecting on-premise and cloud environments, ultimately giving teams the ability to make better, faster decisions and gain a competitive advantage.

With the help of Striim, a unified, real-time data streaming and integration platform, it’s easier than ever to build Smart Data Pipelines connecting clouds, data, and applications. Striim’s Smart Data Pipelines offer real-time data integration to over 100 sources and targets, a SQL-based engine for streaming data applications, high availability and scalability, schema evolution, monitoring, and more. To learn how to build smart data pipelines with Striim today, request a demo or try Striim for free.




