










In today’s fast-paced financial landscape, detecting transaction fraud is essential for protecting institutions and their customers. This article explores how to leverage Striim and SGDClassifier to create a robust fraud detection system that utilizes real-time data streaming and machine learning.
Problem
Transaction fraud detection is a critical responsibility for the IT teams of financial institutions. According to the 2024 Global Financial Crime Report from Nasdaq, an estimated $485.6 billion was lost to fraud scams and bank fraud schemes globally in 2023.
AI and ML help detect fraud, while real-time streaming frameworks like Striim play a key role in delivering financial data to reference and train classification models, enhancing customer protection.
Solution
In this article, I will demonstrate how to use Striim to perform key tasks for fraud detection with machine learning:
- Ingest data using a Change Data Capture (CDC) reader in real time, call the model and deliver alerts to a target such as Email, Slack, Teams or any other target supported by Striim
- Train the model using Striim Initial load app and re-train the model if its accuracy score decreases by using automation via REST APIs
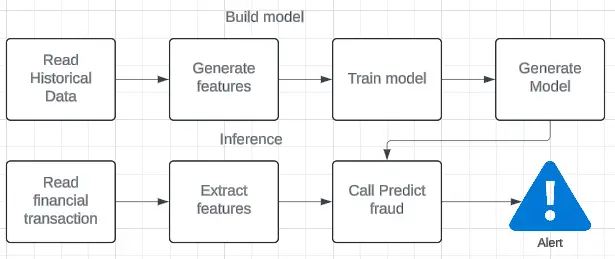
Fraud Detection Approach
In typical credit card transactions, a financial institution’s data science team uses supervised learning to label data records as either fraudulent or legitimate. By carefully analyzing the data, engineers can extract key features that define a fraudulent user profile and behavior, such as personal information, number of orders, order content, payment history, geolocation, and network activity.
For this example, I’m using a dataset from Kaggle, which contains credit card transactions collected from EU retailers approximately 10 years ago. The dataset is already labeled with two classes representing fraudulent and normal transactions. Although the dataset is imbalanced, it serves well for this demonstration. Key fields include purchase value, age, browser type, source, and the class parameter, which indicates normal versus fraudulent transactions.
Picking Classification Model
There are many possibilities for classification using ML. In this example, I evaluated logistic regression and SGDClassifier: https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.SGDClassifier.html. The main difference is that SGDClassifier uses stochastic gradient descent optimization whereas logistic regression uses the logistic function to model binary classification. Many experts consider SGD to be a more optimal approach for larger datasets, which is why it was selected for this application.
Accuracy Measurement
The accuracy score is a metric that measures how often a model correctly predicts the desired outcome. It is calculated by dividing the total number of correct predictions by the total number of predictions. In an ideal scenario, the best possible accuracy is 100% (or 1). However, due to the challenges of obtaining and diagnosing a high-quality dataset, data scientists typically aim for an accuracy greater than 90% (or 0.9).
Training Step
Striim provides the ability to read historical data from various sources including databases, messaging systems, files, and more. In this case, we have historical data stored in the MySQL database, which is a highly popular data source in the FinTech industry. Here’s what architecture with real-time data streaming augmented with training of the ML model looks like:
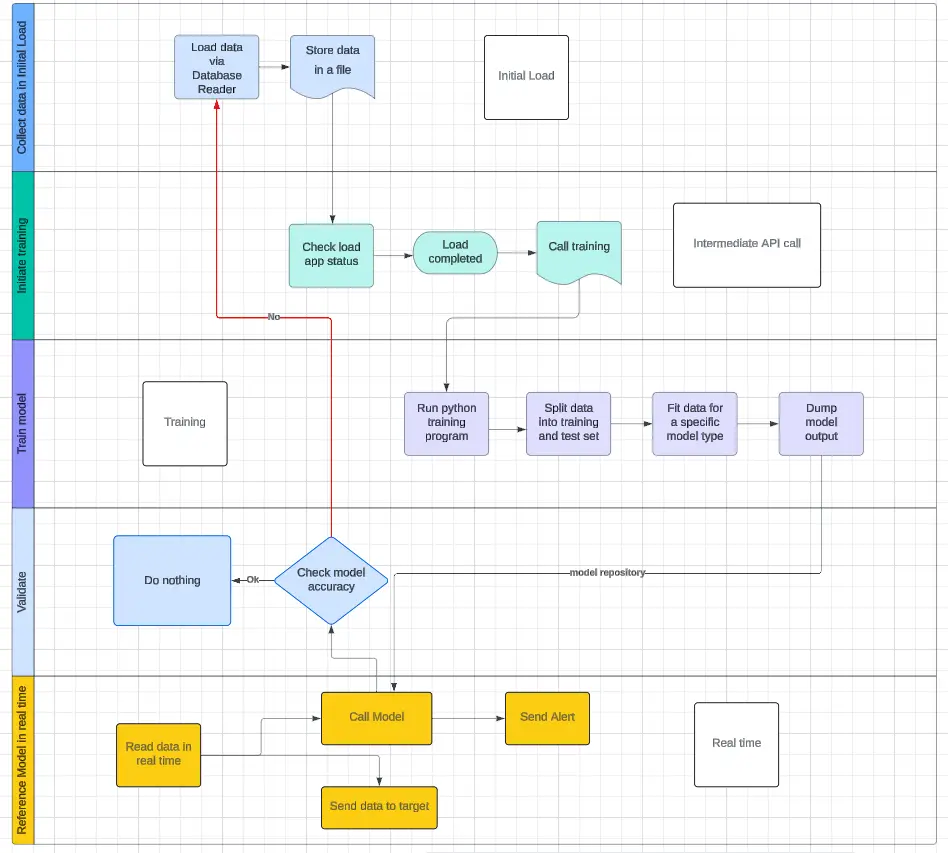
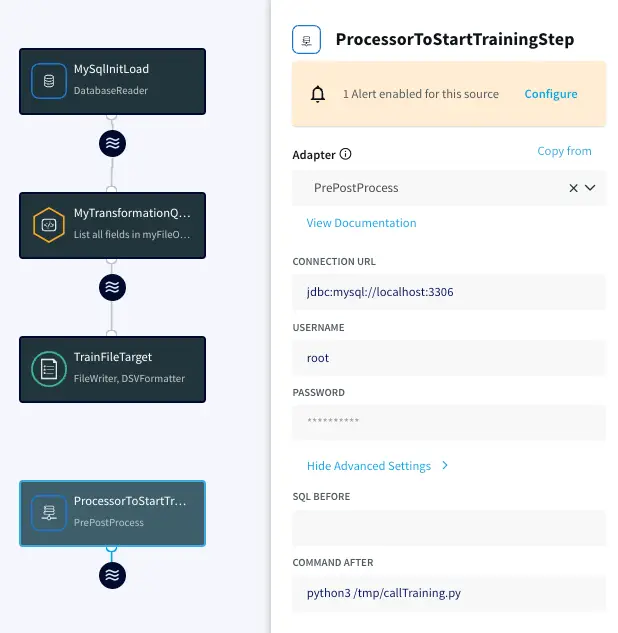
You can achieve this in Striim with an Initial Load application that has a Database reader pointed to the transactions table in MySQL and file target. With Striim’s flexible adapters, data can be loaded virtually from any database of choice and loaded into a local file system, ADLS, S3 or GCS.
Once the data load is completed, the application will change its status from RUNNING to COMPLETED. A script, or in this case, a PS made Open Processor (OP), can capture the status change and call the training Python script.
Additionally, I added a step with CQ (Continuous Query) that allows data scientists to add any transformation to the data in order to prepare the form satisfactory for the training process. This step can be easily implemented using Striim’s Flow Designer, which features a drag and drop interface along with the ability to code data modifications using a combination of SQL-like language and utility function calls.
Model Reference Step
Once the model is trained, we can deploy it in a real-time data CDC application that streams user financial transactions from an operational database. The application calls the model’s predict method, and if fraud is detected, it generates and sends an alert. Additionally, it will check the model accuracy and, if needed, initiate the retraining step described above.
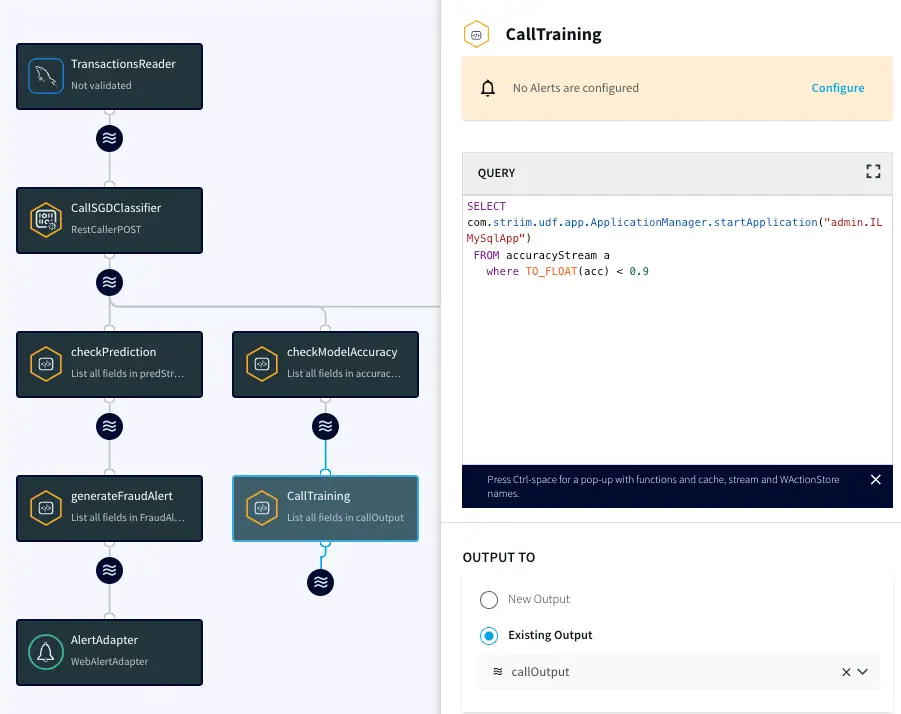
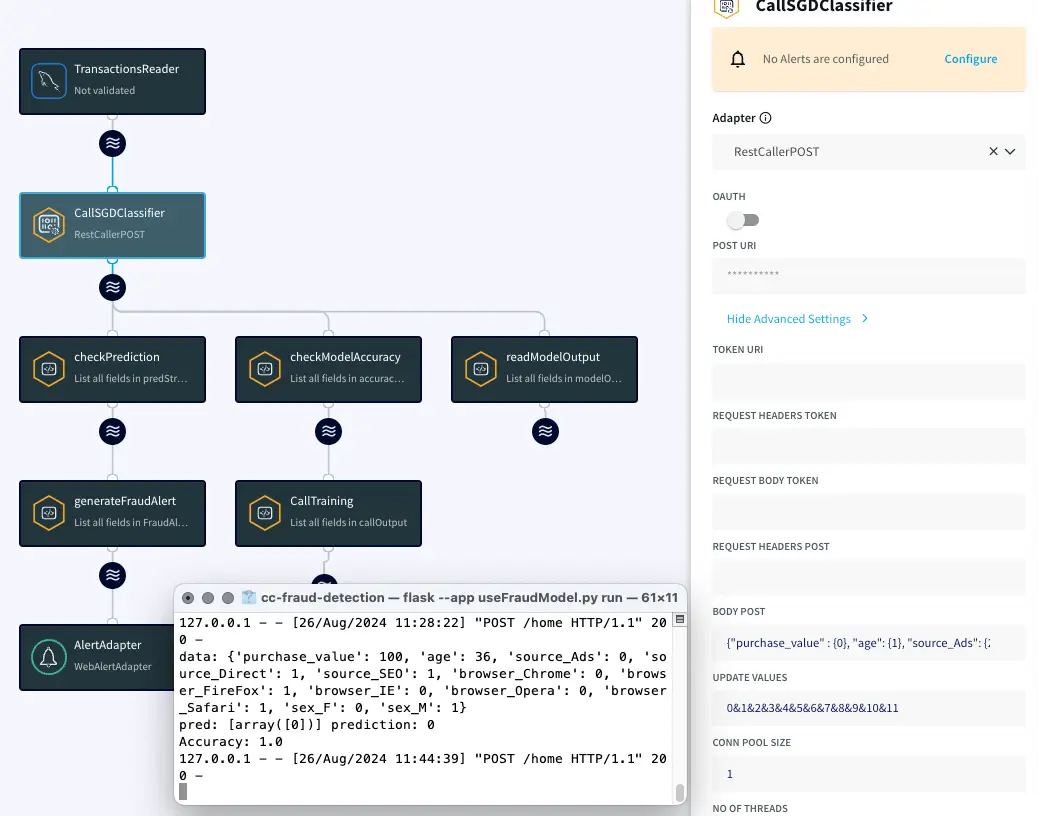
Model Reference App Structure
Flow begins with Striim’s CDC reader that streams financial transactions directly from database binary log. It then invokes our classification model that was trained in the previous step via a REST CALL. In this case, I am using an OP that executes REST POST calls containing parsed transaction values needed for predictions. The model service returns the prediction to be parsed by a query. If fraud is detected, it generates an alert. At the same time, if the model accuracy dips below 90 percent, the Application Manager function can restart a training application called IL MySQL App using an internal management REST API.
Final Thoughts on Leveraging SGDClassifier and Striim for Financial Fraud Detection
This example illustrates how a real-world data streaming application can detect fraud by interacting with a classification model. The application sends alerts when fraud is detected using various Striim alert adapters, including email, web, Slack, or database. Furthermore, if the model’s quality deteriorates, it can retain the model for further evaluation.




