










Overview
ETL (extract, transform, load) has been a standard approach to data integration for decades. But the rise of cloud computing and the need for self-service data integration has enabled the development of new approaches such as ELT (extract, load, transform).
In a world of ever-increasing data sources and formats, both ETL and ELT are essential data science tools. But what are the differences? Is it simply semantics? Or are there significant advantages to taking one approach over the other?
To help you decide on which data integration method to use, we’ll explore ETL and ELT, their strengths and weaknesses, and how to get the most out of both technologies. You’ll learn why ETL is a great choice if you need transformations with business-logic, granular compliance on in-flight data, and low latency in the case of streaming ETL. And we’ll also highlight how ELT is a better option if you require rapid data loading, minimal maintenance, and highly automated workflows.
We’ll also discuss how you can leverage both ETL and ELT for the best of both worlds. Regardless, you will want to select a modern, scalable solution compatible with cloud platforms.
What is ETL? An Overview of the ETL Process
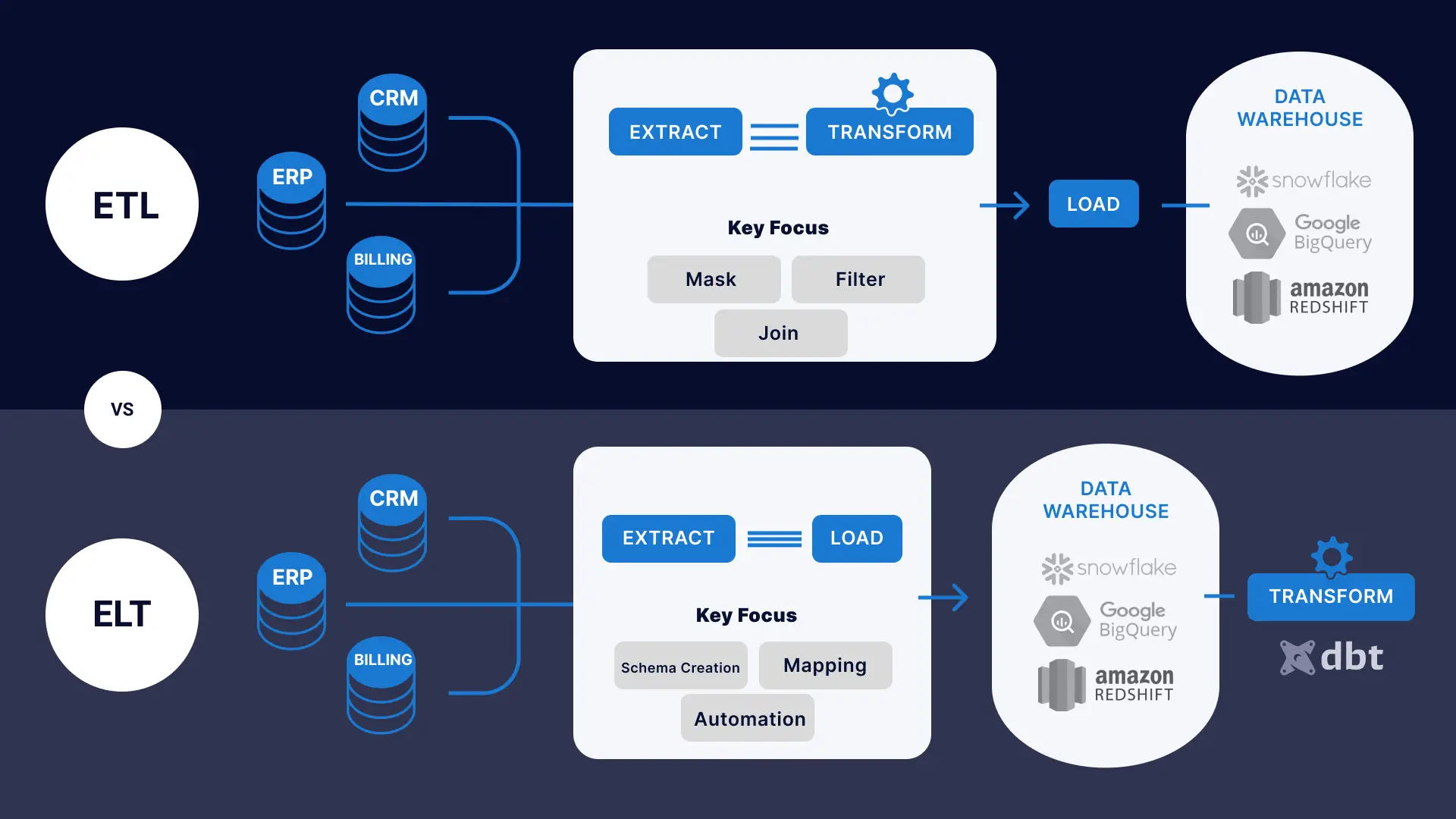
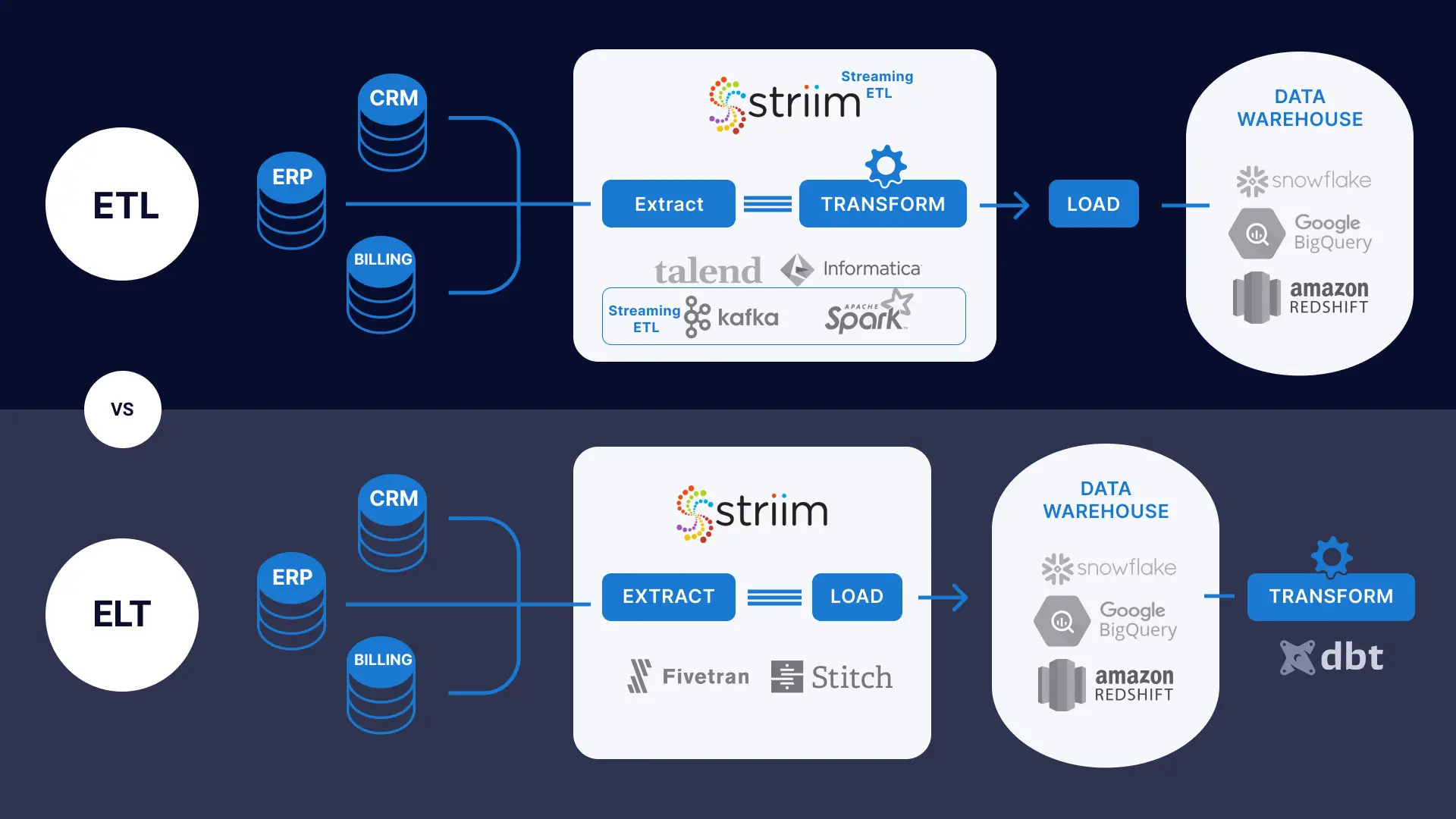
ETL is a data integration process that helps organizations extract data from various sources and bring it into a single target database. The ETL process involves three steps:
- Extraction: Data is extracted from source systems-SaaS, online, on-premises, and others-using database queries or change data capture processes. Following the extraction, the data is moved into a staging area.
- Transformation: Data is then cleaned, processed, and turned into a common format so it can be consumed by a targeted data warehouse, database, or data lake for analysis by a business intelligence platform (Tableau, Looker, etc)
- Loading: Formatted data is loaded into the target system. This process can involve writing to a delimited file, creating schemas in a database, or a new object type in an application.
Advantages of ETL Processes
ETL integration offers several advantages, including:
- Preserves resources: ETL can reduce the volume of data that is stored in the warehouse, helping companies preserve storage, bandwidth, and computation resources in scenarios where they are sensitive to costs on the storage side. Although with commoditized cloud computing engines, this is less of a concern.
- Improves compliance: ETL can mask and remove sensitive data, such as IP or email addresses, before sending it to the data warehouse. Masking, removing, and encrypting specific information helps companies comply with data privacy and protection regulations such as GDPR , HIPAA, and CCPA.
- Well-developed tools: ETL has existed for decades, and there is a range of robust platforms that businesses can deploy to extract, transform, and load data. This makes it easier to set up and maintain an ETL pipeline.
Drawbacks of ETL Processes
Companies that use ETL also have to deal with several drawbacks:
- Legacy ETL is slow: Traditional ETL tools require disk-based staging and transformations.
- Frequent maintenance: ETL data pipelines handle both extraction and transformation. But they have to undergo refactors if analysts require different data types or if the source systems start to produce data with deviating formats and schemas.
- Higher Upfront Cost: Defining business logic and transformations can increase the scope of a data integration project.
How to Modernize ETL with Streaming
The venture capital firm Andreessen Horowitz (a16z) published a piece in which it portrays ETL processes as “brittle,” while ELT pipelines are hailed as more flexible and modern. However there is innovation being delivered in the ETL space as well. Modern streaming ETL platforms can deliver real-time data integration leveraging a technology called in-memory stream processing . Data is loaded in real-time while transformation logic is compiled and processed in-memory (faster than disk-based processing), scaled across multiple nodes to handle high data volumes at sub-second speeds.
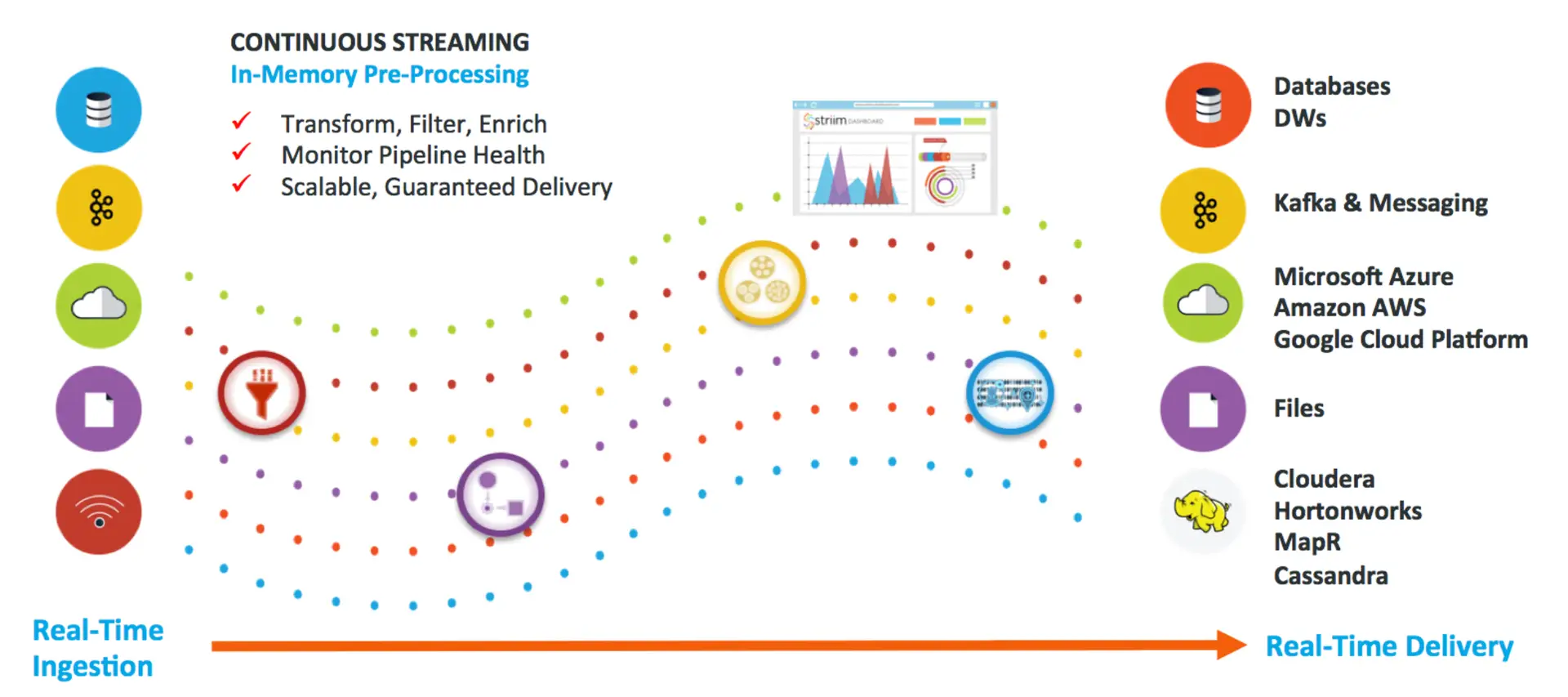
Companies are leveraging tools like Apache Kafka and Spark Streaming to implement streaming ETL pipelines . Products like Striim also offer streaming ETL as more of a holistic, real-time data integration platform .
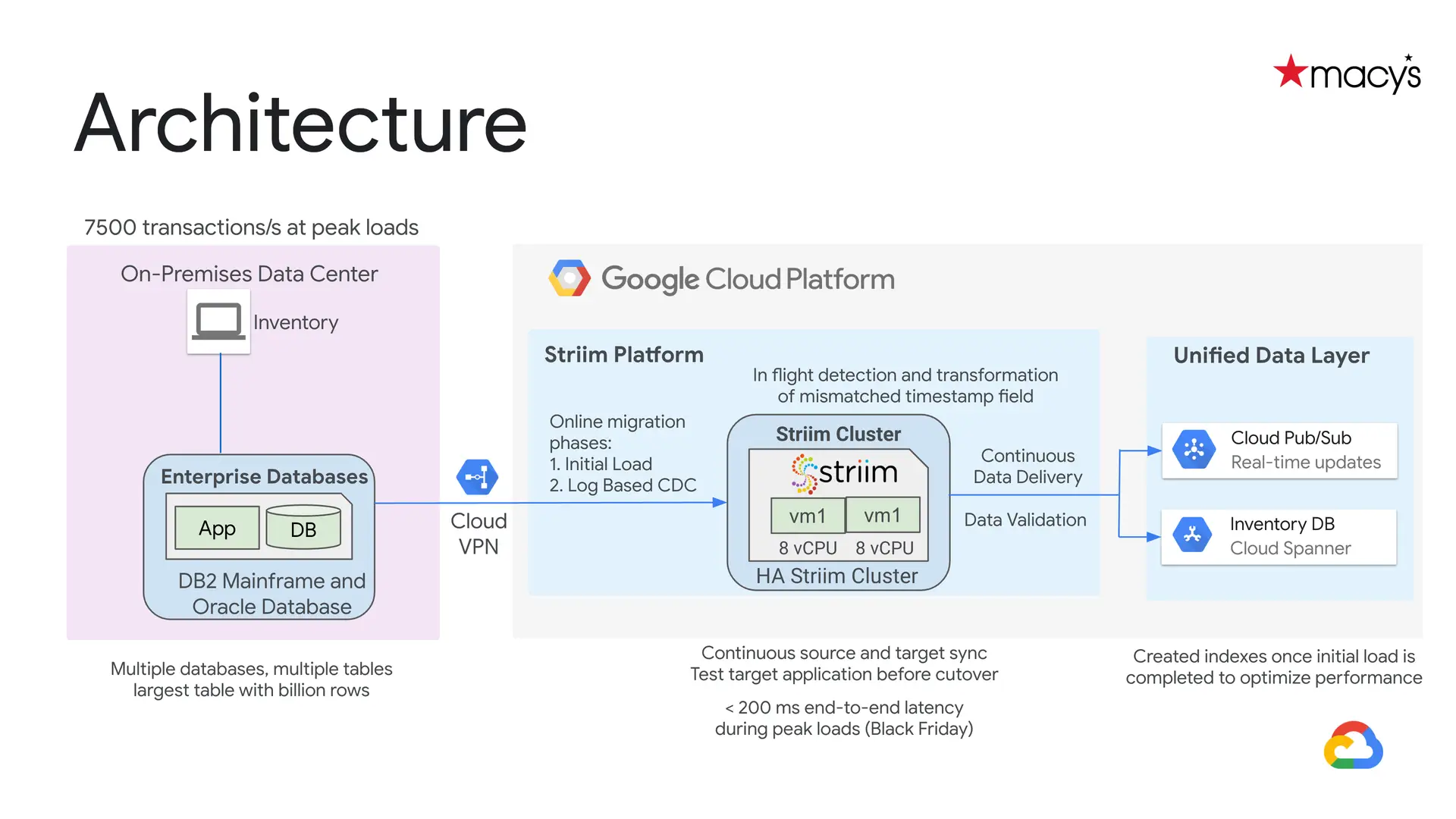
As an example, Macy’s built a cloud replication solution that supported streaming ETL with transformations on in-flight data to detect and resolve mismatched timestamps before replicating it into Google Cloud. This helped them deliver applications that could absorb peak Black Friday workloads using horizontally scalable compute. This is a scenario where a modern, streaming ETL platform outperforms legacy ETL where latency would be too high and data would likely be stale in the target system as a result.
What is ELT? An overview of the ELT process
ELT is a data integration process that transfers data from a source system into a target system without business logic-driven transformations on the data. The ELT process involves three stages:
- Extraction: Raw data is extracted from various sources, such as applications, SaaS, or databases.
- Loading: Data is delivered directly to the target system – typically with schema and data type migration factored into the process.
- Transformation: The target platform can then transform data for reporting purposes. Some companies rely on tools like dbt for transformations on the target.
An ELT pipeline reorders the steps involved in the integration process with the data transformation step occurring at the end instead of in the middle of the process.
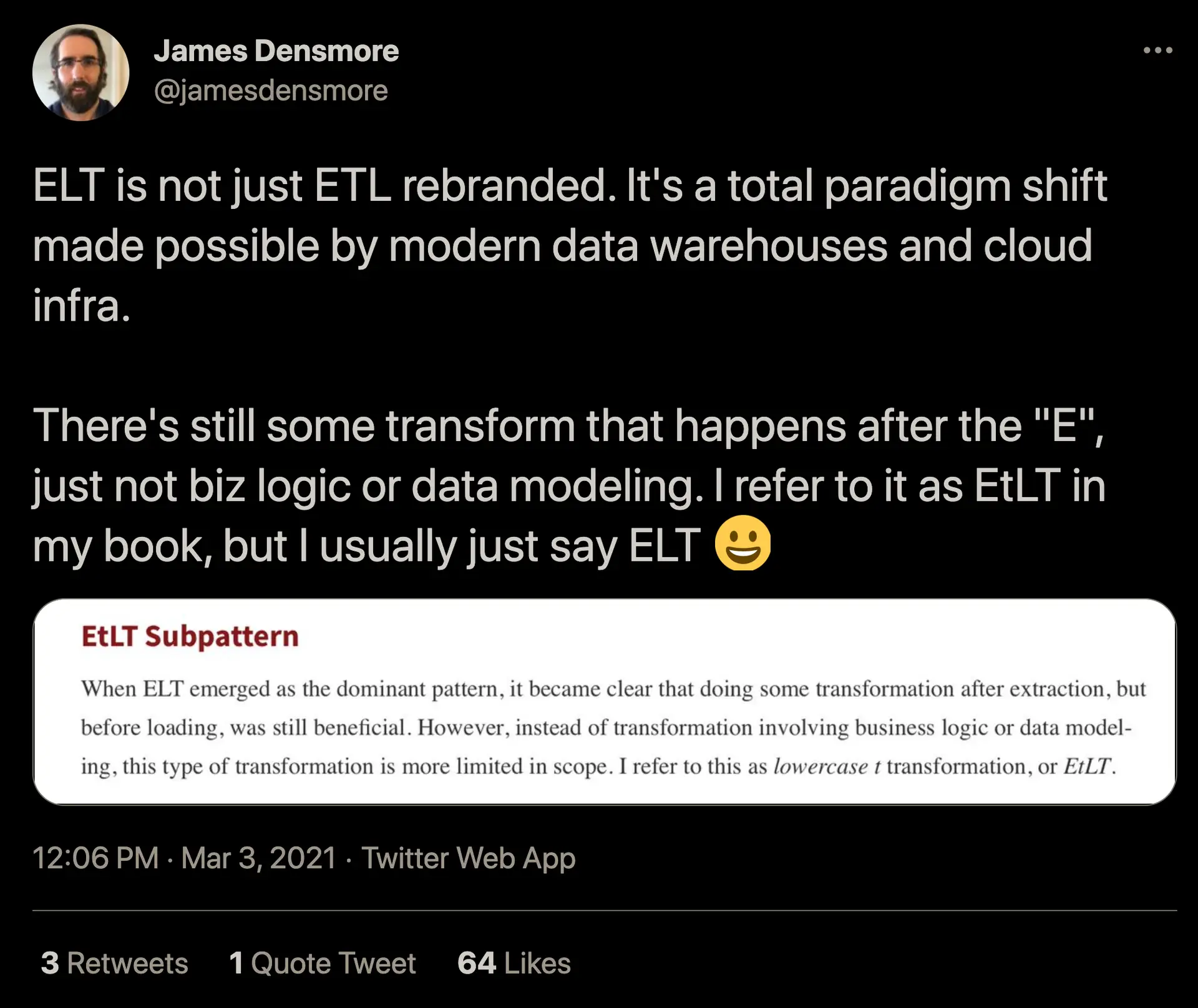
James Densmore – Director of Data Infrastructure at Hubspot – pointed out another nuance of ELT . While there’s no expression of business logic-driven transformations in ELT, there’s still some implicit normalization and conversion of data to match the target data warehouse. He refers to that concept as EtLT in his book on data pipelines .
What Led to the Recent Popularity of ELT
ELT owes its popularity in part to the fact that cloud storage and analytics resources have become more affordable and powerful. This development had two consequences. One, bespoke ETL pipelines have become ill-suited to handle an ever-growing variety and volume of data created by cloud-based services. And second, companies can now afford to store and process all of their unstructured data in the cloud. They no longer need to reduce or filter data during the transformation stage.
Analysts now have more flexibility in deciding how to work with modern data platforms like Snowflake that are well-suited to transform and join data scale.
Advantages of ELT Processes
ELT offers a number of advantages:
- Fast extraction and loading: Data is delivered into the target system immediately with minimal processing in-flight.
- Lower upfront development costs : ELT tools are typically adept at simply plugging source data into the target system with minimal manual work from the user given that user-defined transformations are not required.
- More flexibility: Analysts no longer have to determine what insights and data types they need in advance but can perform transformations on the data as needed in the warehouse with tools like dbt
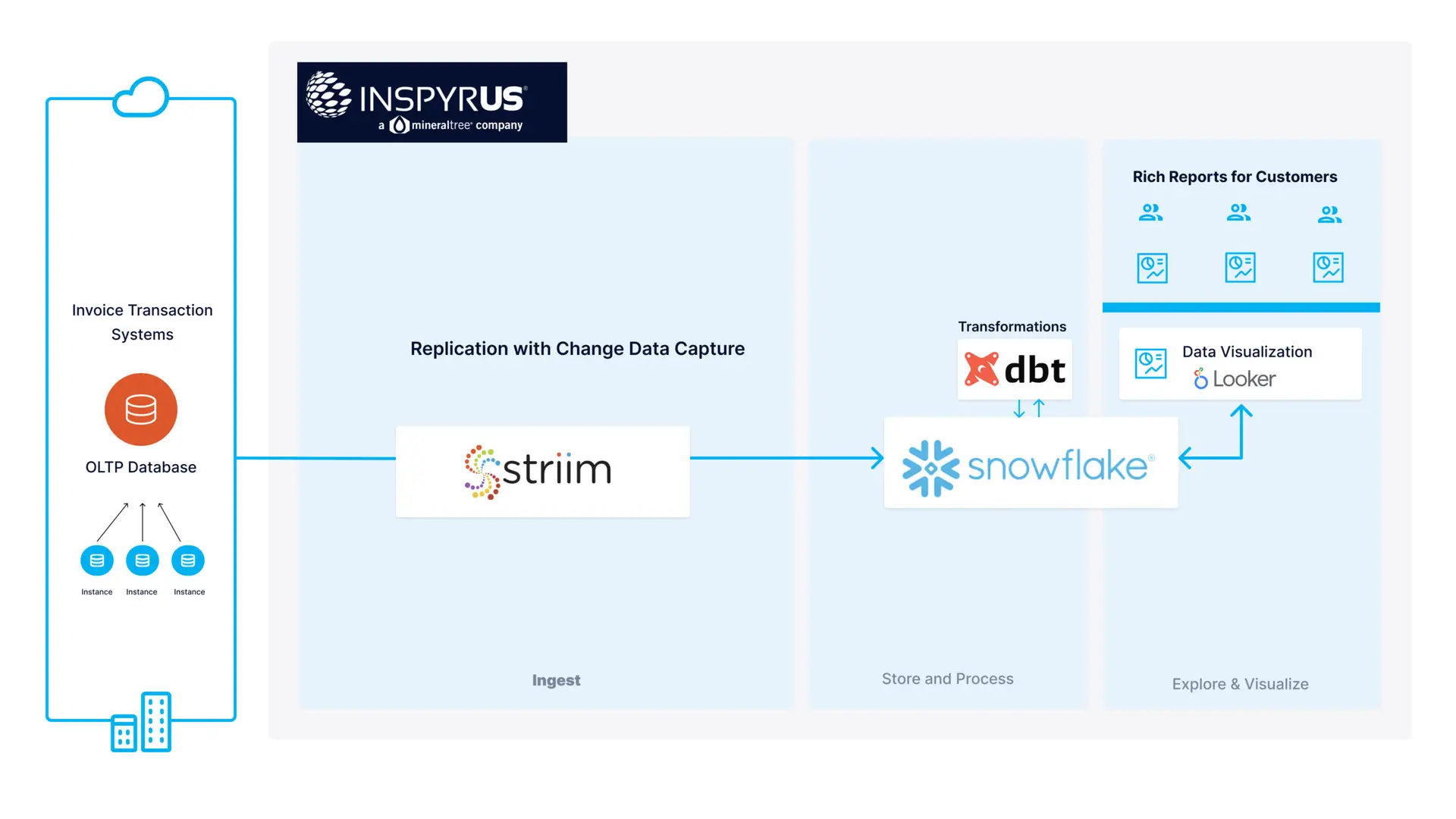
For instance, in database to data warehouse replication scenarios, companies such as Inspyrus use Striim for pure ELT-style replication to Snowflake in concert with dbt for transformations that trigger jobs in Snowflake to normalize the data. This enabled Inspyrus to take a workload that used to take days/weeks and turned it into a near-real-time experience .
Challenges of ELT Processes
ELT is not without challenges, including:
- Overgeneralization: Some modern ELT tools make generalized data management decisions for their users – such as rescanning all tables in the event of a new column or blocking all new transactions in the case of a long-running open transaction. This may work for some users, but could result in unacceptable downtime for others.
- Security gaps: Storing all the data and making it accessible to various users and applications come with security risks. Companies must take steps to ensure their target systems are secure by properly masking and encrypting data.
- Compliance risk: Companies must ensure that their handling of raw data won’t run against privacy regulations and compliance rules such as HIPAA, PCI, and GDPR.
- Increased Latency: In cases where transformations with business logic ARE required in ELT, you must leverage batch jobs in the data warehouse. If latency is a concern, ELT may slow down your operations.
ETL vs ELT Comparison
Differences of ETL versus ELT are evident in a number of parameters. And we summarized some of the key differences between the two data integration approaches in the table below.
.texttable td{padding:10px}
| Parameters | ETL | ELT |
| Order of the Process | Data is transformed at the staging area before being loaded into the target system | Data is extracted and loaded into the target system directly. The transformation step(s) is/are handled in the target. |
| Key Focus | Loading into databases where compute is a precious resource. Transforming data, masking data, normalizing, joining between tables in-flight. | Loading into Data Warehouses. Mapping schemas directly into warehouse. Separating load from transform and execute transforms on the warehouse. |
| Privacy Compliance | Sensitive information can be redacted before loading into the target system | Data is uploaded in its raw form without any sensitive details removed. Masking must be handled in target system. |
| Maintenance Requirements | Transformation logic and schema-change management may require more manual overhead | Maintenance addressed in the data warehouse where transformations are implemented |
| Latency | Generally higher latency with transformations, can be minimized with streaming ETL | Lower latency in cases with little-to-no transformations |
| Data flexibility | Edge cases can be handled with custom rules and logic to maximize uptime | Generalized solutions for edge cases around schema drift and major resyncs – can lead to downtime or increased latency in not carefully planned |
| Analysis flexibility | Use cases and report models have to be defined beforehand | Data can be added at any time with schema evolution. Analysts can build new views off the target warehouse. |
| Scale of Data | Can be bottlenecked by ETL if it is not a scalable, distributed processing system | Implicitly more scalable as less processing takes place in the ELT tool |
Operationalize Your Data Warehouse with “Reverse ETL”
Data warehouses have become the central source of truth, where data from disparate sources is unified to gain business insights. However, data stored in a data warehouse is typically the domain of data analysts who perform queries and create reports. While reports are useful, customer data has even more value if it is immediately actionable by the teams who work with leads and customers (sales, marketing, customer service).
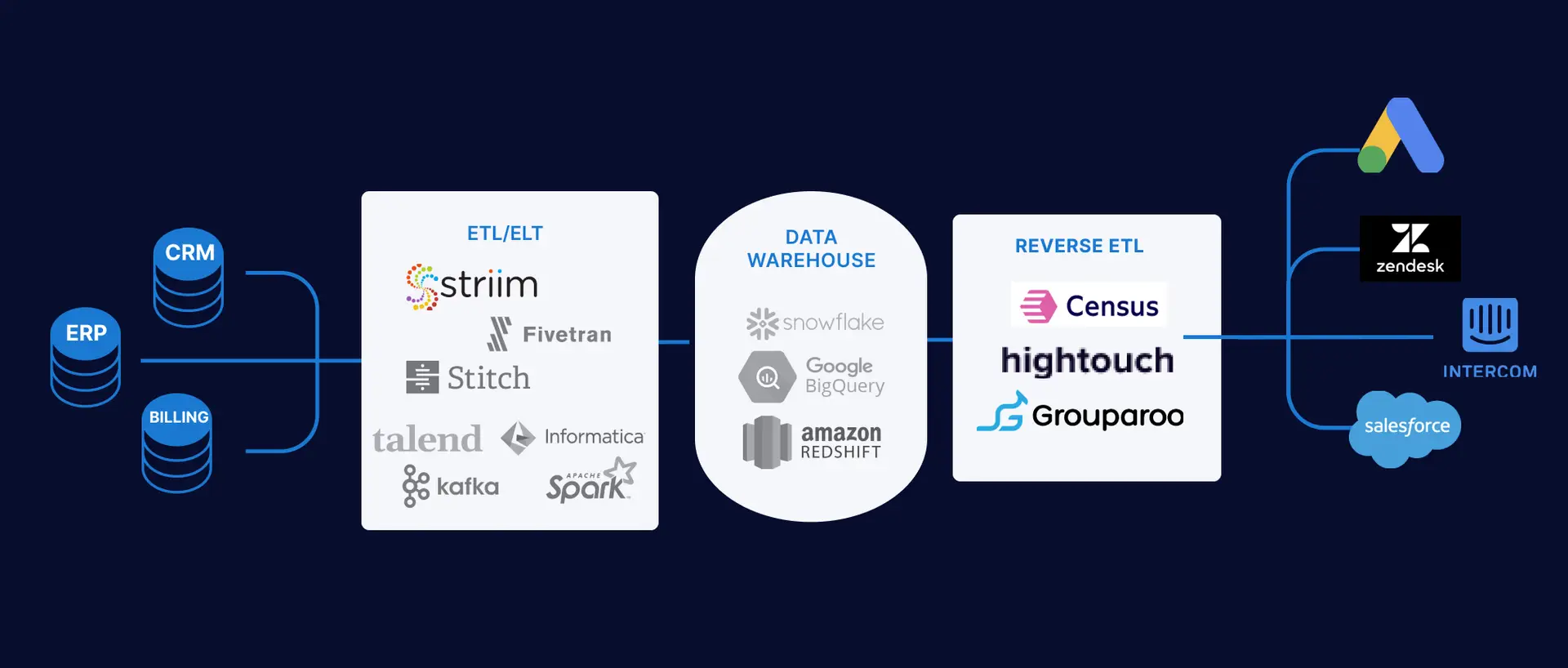
Reverse ETL platforms aim to solve this problem by including connectors to many common sales and marketing applications (such as Zendesk, Salesforce, and Hubspot). They enable real-time or periodic synchronization between data warehouses and apps. Use cases of reverse ETL include:
- Pushing product usage information (e.g. reaching the a-ha moment during a product trial) into Salesforce and creating a task for a sales rep to reach out. Additionally, product usage data can be pushed into Hubspot to add users to a highly-relevant, automated drip campaign.
- Syncing sales activities with Hubspot or Intercom to create personalized email or chat bot flows
- Creating audiences for advertising campaigns based on product usage data, sales activities, and more.
Reverse ETL is the latest trend to emerge in its current state with the modern data ecosystem – however its conceptually not a new category. Data teams have been building applications to operationalize data from OLAP systems before the new ‘Reverse ETL’ stack became popular.
On the other hand, ‘Reverse ETL’ tools are novel in how they integrate with the wave of applications that are designed to leverage 3rd party integrations and a single source of truth of the customer.
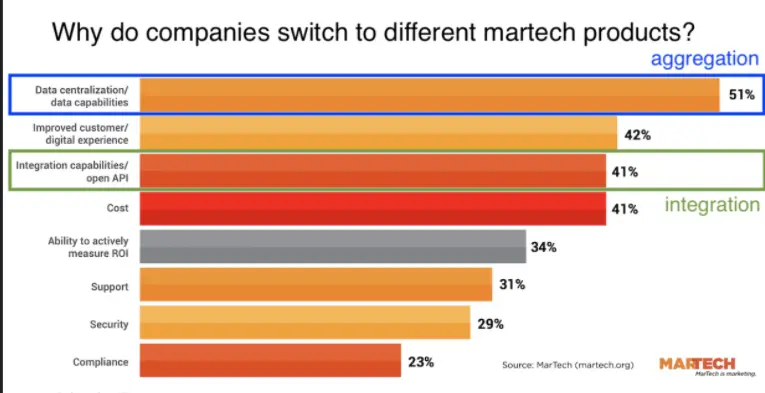
For example, in a survey of marketers who switched MarTech SaaS tools, data centralization and integration was one of the leading drivers of changing their MarTech stack.
No matter whether you choose ETL or ELT, once the data is in your data warehouse, reverse ETL allows you to plug analytical data into operational applications such as Salesforce, Marketo, and Hubspot.
ETL or ELT?
Every data team needs to make trade-offs that are very specific to their own operations. Yet choosing a platform that supports both modern ETL and ELT constructs can allow maximum flexibility in your implementation. You may find that ELT is the right choice to get you started with a low friction, automated solution for data integration. Yet that same topology may require ETL in the future once you discover some in-line transformations that need to be implemented for new use cases and non-data warehousing targets (message busses, applications).
Using Data to Achieve Business Goals
Whether you’re working on data warehousing, machine learning, cloud migration, or other data projects, choosing a data integration approach is of vital importance. ETL is a legacy solution that got upgraded with real-time data integration capabilities. But the power of the cloud has made ELT an exciting option for many companies.
Choosing an appropriate method also depends on your storage technology, data warehouse architecture, and the use of data in day-to-day operations. Knowing the pros and cons of both of these technologies will help you make an informed decision. And armed with powerful data integration solutions, you can more easily harness the power of data and achieve business goals.




