Vector Embeddings
Vector embeddings are dense representations of tokens—such as sentences, paragraphs, or documents—in a high-dimensional vector space, where the dimensions encode abstract features learned during training. They enable efficient similarity comparisons and power applications like search, recommendation systems, and advanced data analysis.
For example: a sample embedding in a 12-dimensional space would look like the following:
[ 0.002243932, -0.009333183, 0.01574578, -0.007790351, -0.004711035, 0.014844206, -0.009739526, -0.03822161, -0.0069014765, -0.028723348, 0.02523134, 0.01814574 ]
Using vector embeddings in your Striim application
Striim enables you to integrate vector embeddings into your streaming applications using the Euclid AI Agent. This agent can be added directly from Flow Designer to generate embeddings from selected data fields and write them to downstream systems. Vector embeddings are commonly stored in vector databases such as Postgres or other supported targets, and Striim provides target adapters for integrating with these systems.
The Euclid AI Agent encapsulates the setup required to connect to an AI model (such as OpenAI or Vertex AI) and generate high-dimensional vector representations from your application data. Once configured, you can use built-in SQL functions to transform and pass selected data to the agent for embedding generation.
You can apply SQL-based transformations to prepare your input data for embedding. To use vector embeddings, first configure the Euclid agent in Flow Designer and specify its parameters. The agent supports both OpenAI and Vertex AI models.
Adding a vector embeddings agent in Flow Designer
You can add the Euclid AI Agent to your application directly from the Flow Designer to generate vector embeddings for real-time data.
Configuring basic parameters for Euclid AI Agent
The following basic parameters for the Euclid (Vector Embeddings) AI Agent are configured in the property panel when the component is selected in the Flow Designer canvas:
Name: specify a unique name for the Euclid component.
Namespace: specify the namespace in which the component operates.
AI Model Provider: select the AI provider. You can select OpenAI or Vertex AI.
Provider-specific settings:
For OpenAI, provide the following:
API key
Model name
Organization ID
For Vertex AI, provide the following:
Project
Model name
Service account key
Location
Publisher
Configuring input for Euclid AI Agent
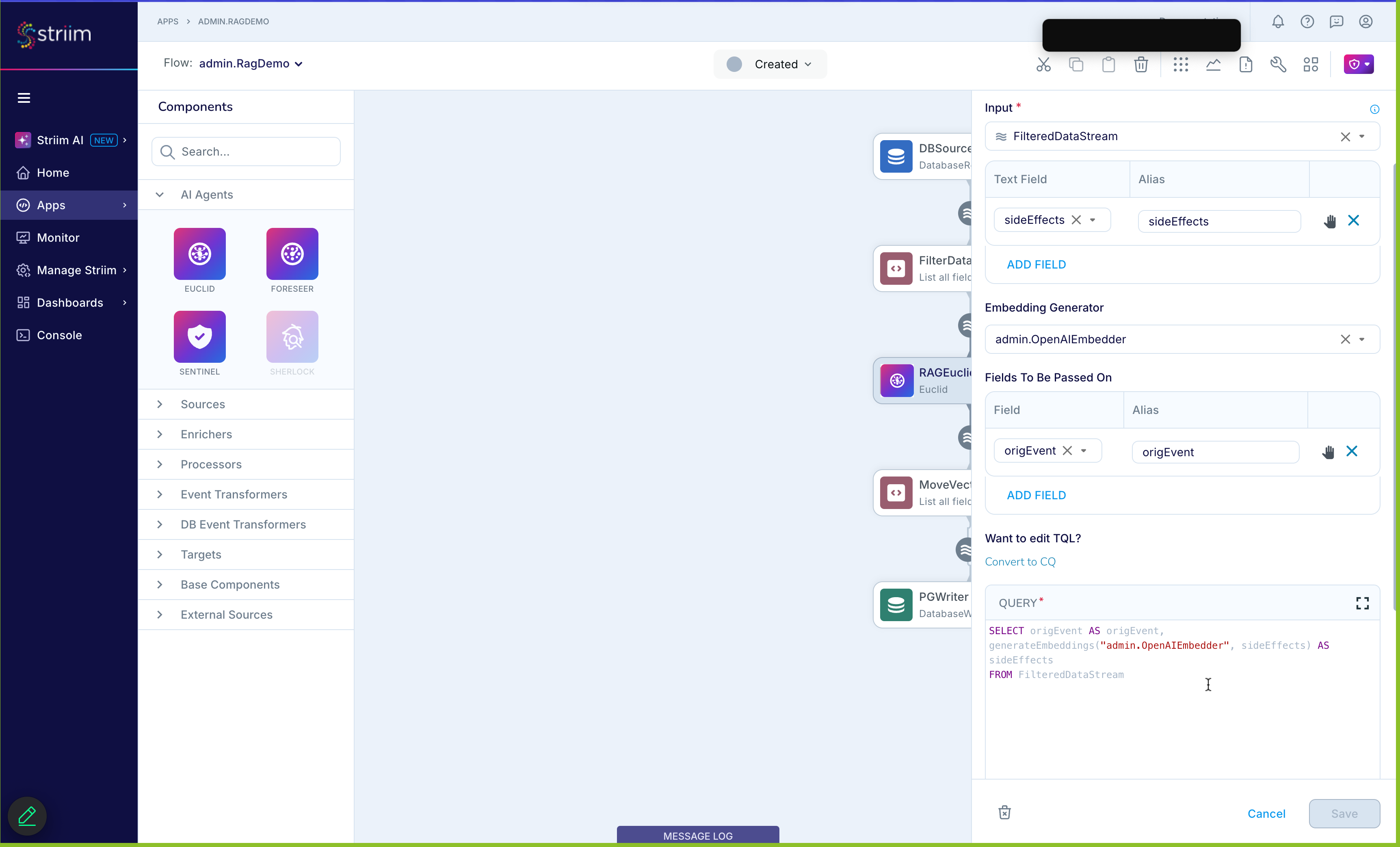
The input configuration for the Euclid AI Agent is performed in the Input panel after you connect an input stream to the Euclid component in Flow Designer. The following options are available:
Input name: specify the name for the input connection.
Text Field / Alias: select the text field to be processed and provide an alias for use in the embeddings output.
Add Fields: optionally select additional fields from the input stream to include in the embeddings output.
Embedding Generator: select or configure the embedding generator as supported by the chosen AI model provider.
Fields to be Passed On: specify a list of field/alias pairs to be included in the output.
Edit TQL: use the “Edit TQL” link in the Input panel to view and edit the generated TQL for the Euclid component.
Creating a vector embeddings generator using TQL
Sample TQL for creating an embeddings generator object:
CREATE OR REPLACE EMBEDDINGGENERATOR OpenAIEmbedder2 USING OpenAI (
modelName: 'text-embedding-ada-002',
apiKey: '**',
'organizationID': 'orgID' // optional
);
CREATE CQ EmbGenCQ
INSERT INTO EmbeddingCDCStream
SELECT putUserData(e, 'embedding', java.util.Arrays.toString(generateEmbeddings("admin.OpenAIEmbedder26",
TO_STRING(GETDATA(e, "description")))))
FROM sourceCDCStream e;
CREATE OR REPLACE TARGET DeliverEmbeddingChangesToPostgresDB USING DatabaseWriter (
Tables: 'AIDEMO.PRODUCTS,aidemo.products2
ColumnMap(product_id=product_id,product_name=product_name,description=description,list_price=
list_price,embedding=@USERDATA(embedding))',
Username: 'example',
Password: 'example',
BatchPolicy: 'EventCount:100,Interval:2',
CommitPolicy: 'EventCount:100,Interval:2',
ConnectionURL: 'jdbc:postgresql://url:port/postgres?stringtype=unspecified'
) INPUT FROM EmbeddingCDCStream;
Supported targets for writing vector embeddings
The following are the supported targets for writing vector embeddings and the recommended data types.
Target type | Recommended data type | Target version |
|---|---|---|
PostgreSQL | vector(<dimension>) | PG13+ (see pgvector documentation) |
Snowflake | Array | |
BigQuery | array<float64> | |
MongoDB Atlas and Cosmos DB for MongoDB vCore | n/a | |
Spanner | Array | |
Databricks | Array | |
Azure SQL database | varchar(max) | |
Fabric Lakehouse and Fabric Data Warehouse | String | |
Single Store MEMSQL | For SingleStore versions 8.5 and above: Vector For SingleStore versions below 8.5: Varchar | Both 8.5 and above and below 8.5 |
Oracle | Vector | Oracle 23ai |
Embeddings model type options and supported models
The following are the model types available and the connection parameters needed:
AI model provider | Embeddings model name (dimensions) | Organization | Required connection parameters |
|---|---|---|---|
OpenAI | GPT text-embedding-ada-002(1536) | OpenAI | API_Key, OrganizationID (optional) |
VertexAI | textembedding-gecko(768) | ProjectId, Location, Provider, ServiceAccountKey |
Model name | Model provider | Token limit | Dimensions |
|---|---|---|---|
text-embedding-ada-002 | OpenAI | 8192 | 1536 |
text-embedding-3-small | OpenAI | 8192 | 1536 |
text-embedding-3-large | OpenAI | 8192 | 3072 |
textembedding-gecko@001 | VertexAI | 3092 | 768 |
textembedding-gecko-multilingual@001 | VertexAI | 3092 | 768 |
textembedding-gecko@002 | VertexAI | 3092 | 768 |
textembedding-gecko@003 | VertexAI | 3092 | 768 |
textembedding-gecko@latest | VertexAI | 3092 | 768 |
textembedding-gecko-multilingual@latest | VertexAI | 3092 | 768 |
Model provider | Model name |
|---|---|
OpenAI | text-embedding-3-small |
VertexAI | textembedding-gecko@003 |
Using batching when generating vector embeddings
Batch processing can improve performance for use cases where you want to generate vector embeddings from streaming data. Batching aggregates the events and data to be embedded, generates the embeddings using the generateEmbeddingsPerBatch function, and flattens the resulting nested data structure into a single list of embeddings.
When using the Euclid AI agent component in Flow Designer, batching is supported if the selected fields (columns) are of type List<String>. The system will automatically generate a continuous query (CQ) that uses the generateEmbeddingsPerBatch function to perform batch processing.
In the Euclid AI agent configuration panel, you can select one or more fields to embed. When batching is enabled (via selecting a list-type field), the Euclid component configures an internal window, batch CQ, and embedding CQ to optimize the embedding process.
Note
Striim currently supports batching only for vector embedding models configured with OpenAI.
// Window to batch CREATE JUMPING WINDOW <window_name> OVER <Stream> KEEP <window_policy>; // Aggregate the events and data to be embedded. CREATE OR REPLACE CQ <CQ_name> INSERT INTO <stream> SELECT list(w) as events, list(TO_STRING(<col_name>)) as data FROM <window_name> w; // Generate embeddings per batch and aggregate into a list. CREATE CQ <CQ_Name> INSERT INTO <out_stream> SELECT makeTupleList(a.events, generateEmbeddingsPerBatch(<namespace>.<object_name>, List<data>)) as objs FROM <int_stream> a; // Flatten the list. CREATE CQ <CQ_name> INSERT INTO <out_stream> SELECT putUserData(cast(origevent.get(0) as com.webaction.proc.events.WAEvent), 'embedding', java.util.Arrays.toString(cast(origevent.get(1) as java.lang.Float[]))) FROM embOut e, ITERATOR (e.objs, java.util.List) as origevent;